溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹XML、JAXP技術和DOM解析的示例分析,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
DOM解析的基本思路:
1、將整個XML文件一次性讀入內存
2、將整個XML看做一棵樹
3、XML中的每一個標簽,屬性,文本都看做是樹上的一個結點
4、然后可以對結點進行增刪改查的操作
上代碼。
1、首先我在D:\ABC中新建了一個文本文件,重命名為stus.xml,以下是文件中的內容
<?xml version = "1.0" encoding = "GBK" ?> <stus class = "S160401A"> <stu num = "001" > <name>張三</name> <age>20</age> <sex>男</sex> </stu> <stu num = "002"> <name>李四</name> <age>21</age> <sex>女</sex> </stu> <stu num = "003"> <name>王五</name> <age>22</age> <sex>男</sex> </stu> </stus>
在第一行是XML聲明<?xml version="1.0" encoding="GBK" ?>,version表示版本號,encoding表示編碼方式,微軟的記事本用的是國標的編碼方式,如果要用UTF-8,則要在另存為窗口中修改編碼方式為UTF-8。
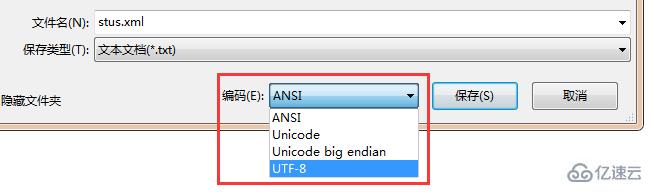
必須且只能有一對根標簽,我寫的根標簽是<stus></stus>。其他的就不多說了。
2、這是一個學生類,定義了一些屬性和get、set方法
<span style="font-size: 16px;">public class Student {
public static String Class;
private String name;
private int num;
private int age;
private char sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
}</span>3、這是用DOM解析的類,看這個類之前還要了解一下。
DocumentBuilderFactory DOM解析器工廠
DocumentBuilder DOM解析器
Document 文檔對象
Node 結點【接口】
Element 元素結點【標簽結點】
Attr 屬性結點
Text 文本結點
Node 是Document,Element,Attr,Text的父接口
NodeList 結點列表
NamedNodeMap 一個結點的所有屬性
<span style="font-size: 16px;">import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import bean.Student;
public class DOMParser {
public static void main(String[] args) throws Exception {
// 得到解析器工廠對象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 生產一個解析器對象
DocumentBuilder builder = factory.newDocumentBuilder();
// 開始解析XML文件,得到解析的結果,是一個Document對象
// Document對象叫做文檔樹對象
Document dom = builder.parse("D:\\ABC\\stus.xml");
// 通過Document對象提取數據
// Document對象的第一個子節點是根節點[根標簽]
Node root = dom.getFirstChild();
// 獲得標簽的名字
String str = root.getNodeName();
// 獲得根節點的屬性
NamedNodeMap attrs = root.getAttributes();
// 強轉成Attr類型 屬性類
Attr attr = (Attr) attrs.getNamedItem("class");
// 獲得屬性里的值
String v = attr.getValue();
System.out.println(v);
// 獲得所有的學生-------------------------------------
NodeList list = root.getChildNodes();
for (int i = 0; i < list.getLength(); i++) {
Node node = list.item(i);
// 判斷是否是標簽結點
if (node instanceof Element) {
Element e = (Element) node;
// 獲得標簽結點里屬性的值
String num = e.getAttribute("num");
System.out.println(num);
// 輸出標簽中的文本
// System.out.println(e.getTextContent());
// 繼續獲得stu的子節點
NodeList nodeList = e.getChildNodes();
for (int j = 0; j < nodeList.getLength(); j++) {
Node n = nodeList.item(j);
if (n instanceof Element) {
Element ele = (Element) n;
// 獲得元素結點的標簽名字
String nodeName = ele.getNodeName();
// 獲得元素結點標簽中的文本
String value = ele.getTextContent();
if (nodeName.equals("name")) {
System.out.println("姓名:" + value);
} else if (nodeName.equals("age")) {
System.out.println("年齡:" + value);
} else if (nodeName.equals("sex")) {
System.out.println("性別:" + value);
}
}
}
}
}
}
}</span>自己在其中總結了一些方法:
DocumentBuilderFactory類:
public static DocumentBuilderFactory newInstance(); //得到解析器工廠對象 public abstract DocumentBuilder newDocumentBuilder(); //生產一個解析器對象
DocumentBuilder類:
public Document parse(String uri); //解析路徑為uri的XML文件,得到解析的結果是一個Document對象
Node類:
public Node getFirstChild(); //得到Document對象的第一個子結點,也就是根結點、或者叫根標簽,在上面的代碼中得到的是stus,看上面的第1點中的XML文件的內容。 public NamedNodeMap getAttributes();//獲得結點的屬性 public NodeList getChildNodes();//獲得所有子結點 public String getNodeName();//獲得標簽的名字 public String getTextContent() throws DOMException;//獲得標簽結點中的文本
NamedNodeMap類:
public Node getNamedItem(String name);//返回所有名字為name的結點
Attr類:
public String getValue();//獲得屬性里的值
NodeList類:
public Node item(int index);//返回第index個結點
Element類:
public String getAttribute(String name);//獲得標簽結點里屬性name的值
以上是“XML、JAXP技術和DOM解析的示例分析”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





