溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“XML是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“XML是什么”吧!
目錄結構:
什么是XML
解析XML
解析XML的兩種方式
使用dom4j解析xml
dom4j的部分API
打印一個XML文件的全部內容
在dom4j中應用XPath解析XML
相關的部分API
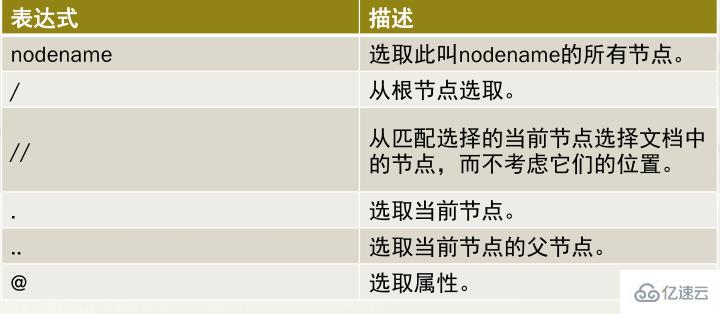
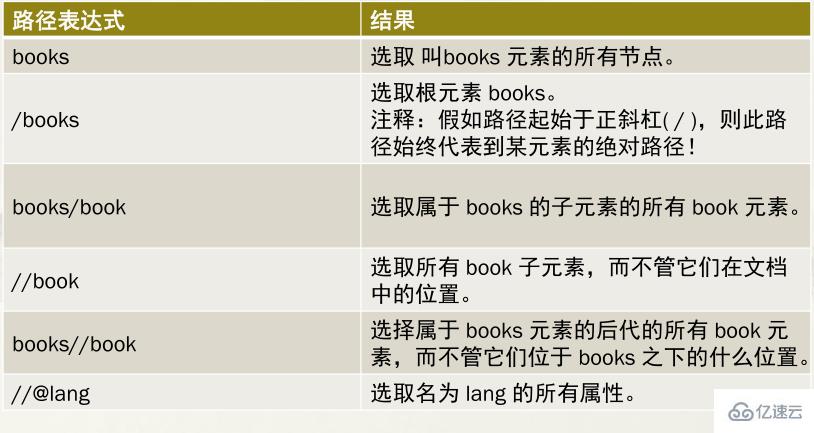
XPath的路徑表達式
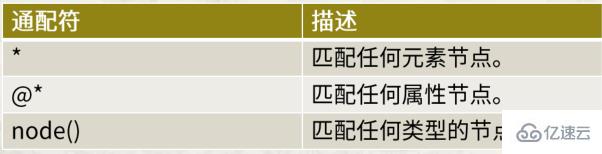
通配符
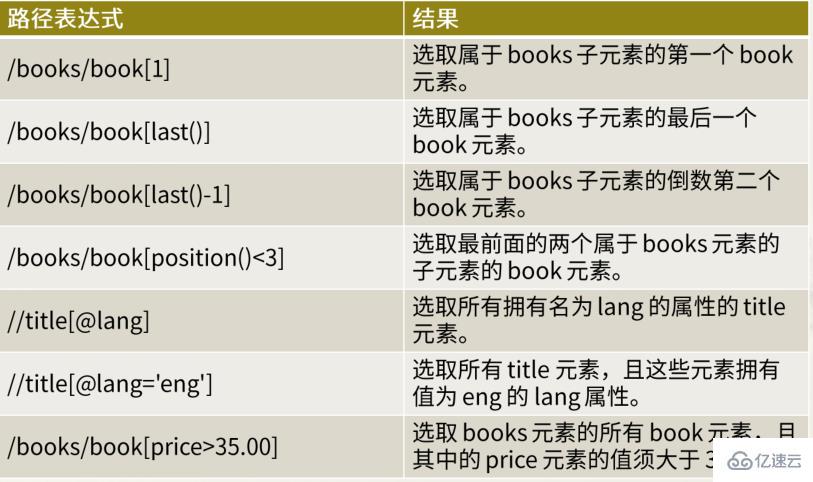
謂語
使用java寫一個XMl文件
將一個帶有書籍信息的List集合解析為XML文件
Schema和DTD的區別
XML(eXtensible markup language) 是一種可擴展的標記語言 ,即使可以自定義標簽的語言。
XML的解析分為兩種方式,分別是SAX和DOM。
DOM:(Document Object Model,就是文檔對象模型),是W3C組織推薦的處理XML的一種方式。使用該方式解析XML文檔,會把文檔中的所有元素,按照其出現的層次關系,在內存中構造出樹形結構。因此對內存的壓力大,解析熟讀慢,優點就是可以遍歷和修改節點的內容。
SAX:(Simple API for XML) 是一種XML解析的替代方法。相比較于DOM,解析速度更快,內存的壓力更小;缺點就是不能修改節點的內容。
在使用dom4j解析XML之前需要導入相關的工具包,比如筆者的: dom4j-1.6.1.jar 包
//創建SAXReader,是dom4j包提供的解析器SAXReader reader=new SAXReader();//讀取指定的文件Document doc=reader.read(new File(filename)); Document Document getRootElement() 用于獲取根元素 Element Element element(String name) 獲取元素下指定名稱的子元素 List<Element> elements() 獲取元素下所有的子元素 String getName() 獲取元素名 String getText() 獲取元素文本內容 String elementText(String name) 獲取子元素文本內容 Attribute attribute(String) 獲取元素的屬性 String attributeValue(String name) 獲取元素的屬性值 Attribute String getName() 獲取屬性的名字 String getValue() 獲取屬性的值
pricties.xml文件直接位于項目下


<?xml version="1.0" encoding="utf-8" ?><books id="a"> <book id="b"><name id="c_1" name="c_2">三國演繹</name><author id="d_1" name="d_2" >羅貫中</author><price id="e">58.8</price> </book> <book id="f_1" name="f_2"><name id="g">水滸傳</name><author id="h">施耐庵</author><price id="i">49.8</price> </book> <book id="j_1" name="j_2"><name id="k">西游記</name><author id="l">吳承恩</author><price id="m">100.1</price><order>1</order> </book></books>
pricties.xml


import java.io.File;import java.util.List;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class ParseXML {public static void main(String[] args) {//創建SAXReader對象SAXReader saxr=new SAXReader();
Document docu=null;try{//讀取指定的文件,相對于項目路徑docu=saxr.read(new File("pricties.xml"));//獲得元素的文件的根節點Element e=docu.getRootElement();
searchAllElement(e);
}catch(Exception e){
e.printStackTrace();
}
} public static void searchAllElement(Element e){//獲得當前元素下的所有子元素,并存儲到集合中List<Element> elements=e.elements();
System.out.print("<"+e.getName());//打印開始標記List<Attribute> atrs=e.attributes();//打印該標記下的所有屬性for(Attribute att:atrs){
System.out.print(" "+att.getName()+"=\""+att.getValue()+"\"");
}
System.out.println(">"); //如果集合的大小為0,表示該集合下沒有子元素了if(elements.size()==0){
System.out.println(e.getText());//打印文本信息System.out.println("</"+e.getName()+">");//打印結束標記return;//退出當前層方法 } //遞歸每一個子元素for(Element ele:elements){
searchAllElement(ele);
}
System.out.println("</"+e.getName()+">");//打印結束標記 }
}parseXML.xml
首先需要在dom4j基礎上引入相應的jar包,比如讀者的: jaxen-1.1-beta-6.jar
Document List<Node> selectNodes(String xpath) Node selectSingleNode(String xpath)

謂語是用來查找某個特定的節點或是包含某個指定的值的節點
謂語被嵌在方括號中


package com.xdl.xml;public class Book {private String name;private String author;private String price;public Book() {super();
}public Book(String name, String author, String price) {super();
setName(name);
setAuthor(author);
setPrice(price);
}/** * @return the name */public String getName() {return name;
}/** * @param name the name to set */public void setName(String name) {this.name = name;
}/** * @return the author */public String getAuthor() {return author;
}/** * @param author the author to set */public void setAuthor(String author) {this.author = author;
}/** * @return the price */public String getPrice() {return price;
}/** * @param price the price to set */public void setPrice(String price) {this.price = price;
}
}Book.java


package com.xdl.xml;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.ArrayList;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;import org.dom4j.io.XMLWriter;public class WriteXML {public static void main(String[] args) {//創建一個Book集合用于存儲書籍信息List<Book> list_books=new ArrayList<Book>();//插入書籍信息for(int i=0;i<6;i++){
Book book=new Book("jame"+i,"author"+i,""+i);
list_books.add(book);
} //創建一個文檔對象Document doc=DocumentHelper.createDocument();//創建一個根節點Element books=DocumentHelper.createElement("books"); //獲得書籍集合的大小int size=list_books.size();for(int i=0;i<size;i++){//創建一個book節點Element book=books.addElement("book");//創建一個name節點Element name=book.addElement("name");//創建一個author節點Element author=book.addElement("author");//創建一個price節點Element price=book.addElement("price");
name.setText(list_books.get(i).getName());
author.setText(list_books.get(i).getAuthor());
price.setText(list_books.get(i).getPrice());
}//設置文檔根節點 doc.setRootElement(books); try {//如果文件不存在,會自動創建FileOutputStream fos = new FileOutputStream(new File("books.xml"));
XMLWriter xmlw = new XMLWriter(fos);
xmlw.write(doc);
xmlw.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}WriteXML.java
Schema是對XML文檔結構的定義和描述,其主要的作用是用來約束XML文件,并驗證XML文件有效性。DTD的作用是定義XML的合法構建模塊,它使用一系列的合法元素來定義文檔結構。它們之間的區別有下面幾點:
1、Schema本身也是XML文檔,DTD定義跟XML沒有什么關系,Schema在理解和實際應用有很多的好處。
2、DTD文檔的結構是“平鋪型”的,如果定義復雜的XML文檔,很難把握各元素之間的嵌套關系;Schema文檔結構性強,各元素之間的嵌套關系非常直觀。
3、DTD只能指定元素含有文本,不能定義元素文本的具體類型,如字符型、整型、日期型、自定義類型等。Schema在這方面比DTD強大。
4、Schema支持元素節點順序的描述,DTD沒有提供無序情況的描述,要定義無序必需窮舉排列的所有情況。Schema可以利用xs:all來表示無序的情況。
5、對命名空間的支持。DTD無法利用XML的命名空間,Schema很好滿足命名空間。并且,Schema還提供了include和import兩種引用命名空間的方法。
感謝各位的閱讀,以上就是“XML是什么”的內容了,經過本文的學習后,相信大家對XML是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





