溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文主要給大家簡單講講mysql鎖機制原理及用法,相關專業術語大家可以上網查查或者找一些相關書籍補充一下,這里就不涉獵了,我們就直奔主題吧,希望mysql鎖機制原理及用法這篇文章可以給大家帶來一些實際幫助。 Mysql用到了很多這種鎖機制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖。這些鎖統稱為悲觀鎖(Pessimistic Lock)。
InnoDB鎖
InnoDB與MyISAM的最大不同有兩點:
一是支持事務(TRANSACTION);
二是采用了行級鎖。行級鎖與表級鎖本來就有許多不同之處,另外,事務的引入也帶來了一些新問題。
1、事務(Transaction)及其ACID屬性
事務是由一組SQL語句組成的邏輯處理單元,事務具有4屬性,通常稱為事務的ACID屬性。
1、原子性(Actomicity):事務是一個原子操作單元,其對數據的修改,要么全都執行,要么全都不執行。
2、一致性(Consistent):在事務開始和完成時,數據都必須保持一致狀態。這意味著所有相關的數據規則都必須應用于事務的修改,以操持完整性;事務結束時,所有的內部數據結構(如B樹索引或雙向鏈表)也都必須是正確的。
3、隔離性(Isolation):數據庫系統提供一定的隔離機制,保證事務在不受外部并發操作影響的“獨立”環境執行。這意味著事務處理過程中的中間狀態對外部是不可見的,反之亦然。
4、持久性(Durable):事務完成之后,它對于數據的修改是永久性的,即使出現系統故障也能夠保持。

2、并發事務帶來的問題
相對于串行處理來說,并發事務處理能大大增加數據庫資源的利用率,提高數據庫系統的事務吞吐量,從而可以支持更多的用戶。但并發事務處理也會帶來一些問題,主要包括以下幾種情況。
1、更新丟失(Lost Update):當兩個或多個事務選擇同一行,然后基于最初選定的值更新該行時,由于每個事務都不知道其他事務的存在,就會發生丟失更新問題——最后的更新覆蓋了其他事務所做的更新。例如,兩個編輯人員制作了同一文檔的電子副本。每個編輯人員獨立地更改其副本,然后保存更改后的副本,這樣就覆蓋了原始文檔。最后保存其更改副本的編輯人員覆蓋另一個編輯人員所做的修改。如果在一個編輯人員完成并提交事務之前,另一個編輯人員不能訪問同一文件,則可避免此問題。
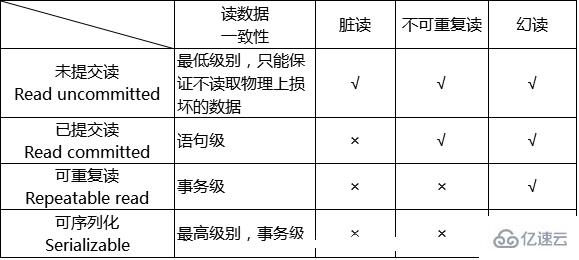
2、臟讀(Dirty Reads):一個事務正在對一條記錄做修改,在這個事務并提交前,這條記錄的數據就處于不一致狀態;這時,另一個事務也來讀取同一條記錄,如果不加控制,第二個事務讀取了這些“臟”的數據,并據此做進一步的處理,就會產生未提交的數據依賴關系。這種現象被形象地叫做“臟讀”。
3、不可重復讀(Non-Repeatable Reads):一個事務在讀取某些數據已經發生了改變、或某些記錄已經被刪除了!這種現象叫做“不可重復讀”。
4、幻讀(Phantom Reads):一個事務按相同的查詢條件重新讀取以前檢索過的數據,卻發現其他事務插入了滿足其查詢條件的新數據,這種現象就稱為“幻讀”。
3、事務隔離級別
在并發事務處理帶來的問題中,“更新丟失”通常應該是完全避免的。但防止更新丟失,并不能單靠數據庫事務控制器來解決,需要應用程序對要更新的數據加必要的鎖來解決,因此,防止更新丟失應該是應用的責任。
“臟讀”、“不可重復讀”和“幻讀”,其實都是數據庫讀一致性問題,必須由數據庫提供一定的事務隔離機制來解決。數據庫實現事務隔離的方式,基本可以分為以下兩種。
1、一種是在讀取數據前,對其加鎖,阻止其他事務對數據進行修改。
2、另一種是不用加任何鎖,通過一定機制生成一個數據請求時間點的一致性數據快照(Snapshot),并用這個快照來提供一定級別(語句級或事務級)的一致性讀取。從用戶的角度,好像是數據庫可以提供同一數據的多個版本,因此,這種技術叫做數據多版本并發控制(MultiVersion Concurrency Control,簡稱MVCC或MCC),也經常稱為多版本數據庫。
在MVCC并發控制中,讀操作可以分成兩類:快照讀 (snapshot read)與當前讀 (current read)。快照讀,讀取的是記錄的可見版本 (有可能是歷史版本),不用加鎖。當前讀,讀取的是記錄的最新版本,并且,當前讀返回的記錄,都會加上鎖,保證其他事務不會再并發修改這條記錄。
在一個支持MVCC并發控制的系統中,哪些讀操作是快照讀?哪些操作又是當前讀呢?以MySQL InnoDB為例:
快照讀:簡單的select操作,屬于快照讀,不加鎖。(當然,也有例外)
select * from table where ?;
當前讀:特殊的讀操作,插入/更新/刪除操作,屬于當前讀,需要加鎖。
下面語句都屬于當前讀,讀取記錄的最新版本。并且,讀取之后,還需要保證其他并發事務不能修改當前記錄,對讀取記錄加鎖。其中,除了第一條語句,對讀取記錄加S鎖 (共享鎖)外,其他的操作,都加的是X鎖 (排它鎖)。
數據庫的事務隔離越嚴格,并發副作用越小,但付出的代價也就越大,因為事務隔離實質上就是使事務在一定程度上 “串行化”進行,這顯然與“并發”是矛盾的。同時,不同的應用對讀一致性和事務隔離程度的要求也是不同的,比如許多應用對“不可重復讀”和“幻讀”并不敏 感,可能更關心數據并發訪問的能力。
為了解決“隔離”與“并發”的矛盾,ISO/ANSI SQL92定義了4個事務隔離級別,每個級別的隔離程度不同,允許出現的副作用也不同,應用可以根據自己的業務邏輯要求,通過選擇不同的隔離級別來平衡 “隔離”與“并發”的矛盾。下表很好地概括了這4個隔離級別的特性。
獲取InonoD行鎖爭用情況
可以通過檢查InnoDB_row_lock狀態變量來分析系統上的行鎖的爭奪情況:
mysql> show status like 'innodb_row_lock%';

如果發現鎖爭用比較嚴重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比較高,還可以通過設置InnoDB Monitors來進一步觀察發生鎖沖突的表、數據行等,并分析鎖爭用的原因。
InnoDB的行鎖模式及加鎖方法
InnoDB實現了以下兩種類型的行鎖。
共享鎖(s):又稱讀鎖。允許一個事務去讀一行,阻止其他事務獲得相同數據集的排他鎖。若事務T對數據對象A加上S鎖,則事務T可以讀A但不能修改A,其他事務只能再對A加S鎖,而不能加X鎖,直到T釋放A上的S鎖。這保證了其他事務可以讀A,但在T釋放A上的S鎖之前不能對A做任何修改。
排他鎖(X):又稱寫鎖。允許獲取排他鎖的事務更新數據,阻止其他事務取得相同的數據集共享讀鎖和排他寫鎖。若事務T對數據對象A加上X鎖,事務T可以讀A也可以修改A,其他事務不能再對A加任何鎖,直到T釋放A上的鎖。
對于共享鎖大家可能很好理解,就是多個事務只能讀數據不能改數據。
對于排他鎖大家的理解可能就有些差別,我當初就犯了一個錯誤,以為排他鎖鎖住一行數據后,其他事務就不能讀取和修改該行數據,其實不是這樣的。排他鎖指的是一個事務在一行數據加上排他鎖后,其他事務不能再在其上加其他的鎖。mysql InnoDB引擎默認的修改數據語句:update,delete,insert都會自動給涉及到的數據加上排他鎖,select語句默認不會加任何鎖類型,如果加排他鎖可以使用select …for update語句,加共享鎖可以使用select … lock in share mode語句。所以加過排他鎖的數據行在其他事務種是不能修改數據的,也不能通過for update和lock in share mode鎖的方式查詢數據,但可以直接通過select …from…查詢數據,因為普通查詢沒有任何鎖機制。
另外,為了允許行鎖和表鎖共存,實現多粒度鎖機制,InnoDB還有兩種內部使用的意向鎖(Intention Locks),這兩種意向鎖都是表鎖。
意向共享鎖(IS):事務打算給數據行共享鎖,事務在給一個數據行加共享鎖前必須先取得該表的IS鎖。意向排他鎖(IX):事務打算給數據行加排他鎖,事務在給一個數據行加排他鎖前必須先取得該表的IX鎖。
InnoDB行鎖模式兼容性列表:
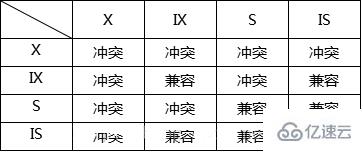
如果一個事務請求的鎖模式與當前的鎖兼容,InnoDB就請求的鎖授予該事務;反之,如果兩者兩者不兼容,該事務就要等待鎖釋放。
意向鎖是InnoDB自動加的,不需用戶干預。對于UPDATE、DELETE和INSERT語句,InnoDB會自動給涉及數據集加排他鎖(X);對于普通SELECT語句,InnoDB不會加任何鎖。
事務可以通過以下語句顯式給記錄集加共享鎖或排他鎖:
1、共享鎖(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE。
2、排他鎖(X):SELECT * FROM table_name WHERE ... FOR UPDATE。
用SELECT ... IN SHARE MODE獲得共享鎖,主要用在需要數據依存關系時來確認某行記錄是否存在,并確保沒有人對這個記錄進行UPDATE或者DELETE操作。但是如果當前事務也需要對該記錄進行更新操作,則很有可能造成死鎖,對于鎖定行記錄后需要進行更新操作的應用,應該使用SELECT… FOR UPDATE方式獲得排他鎖。
InnoDB行鎖實現方式
InnoDB行鎖是通過給索引上的索引項加鎖來實現的,這一點MySQL與Oracle不同,后者是通過在數據塊中對相應數據行加鎖來實現的。InnoDB這種行鎖實現特點意味著:只有通過索引條件檢索數據,InnoDB才使用行級鎖,否則,InnoDB將使用表鎖!
在實際應用中,要特別注意InnoDB行鎖的這一特性,不然的話,可能導致大量的鎖沖突,從而影響并發性能。下面通過一些實際例子來加以說明。
(1)在不通過索引條件查詢的時候,InnoDB確實使用的是表鎖,而不是行鎖。
mysql> create table tab_no_index(id int,name varchar(10)) engine=innodb; Query OK, 0 rows affected (0.15 sec) mysql> insert into tab_no_index values(1,'1'),(2,'2'),(3,'3'),(4,'4');Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0
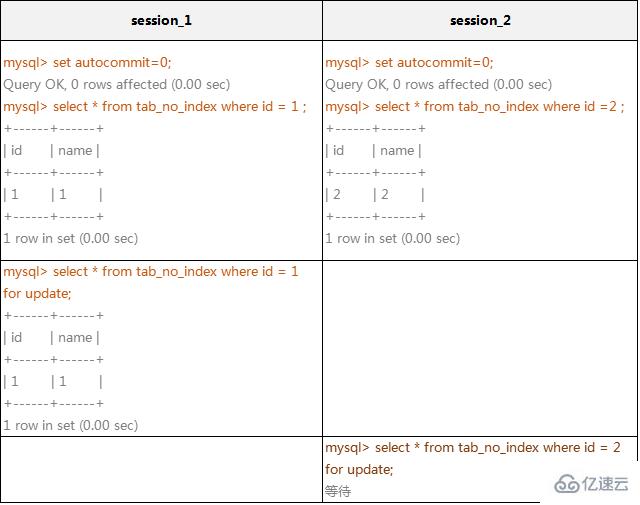
在上面的例子中,看起來session_1只給一行加了排他鎖,但session_2在請求其他行的排他鎖時,卻出現了鎖等待!原因就是在沒有索引的情況下,InnoDB只能使用表鎖。當我們給其增加一個索引后,InnoDB就只鎖定了符合條件的行,如下例所示:
創建tab_with_index表,id字段有普通索引:
mysql> create table tab_with_index(id int,name varchar(10)) engine=innodb; mysql> alter table tab_with_index add index id(id);

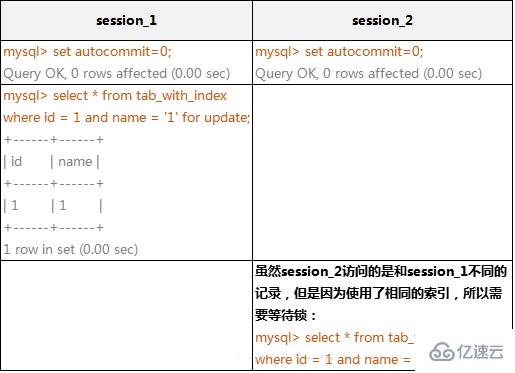
(2)由于MySQL的行鎖是針對索引加的鎖,不是針對記錄加的鎖,所以雖然是訪問不同行的記錄,但是如果是使用相同的索引鍵,是會出現鎖沖突的。應用設計的時候要注意這一點。
在下面的例子中,表tab_with_index的id字段有索引,name字段沒有索引:
mysql> alter table tab_with_index drop index name; 1 Query OK, 4 rows affected (0.22 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql> insert into tab_with_index values(1,'4'); 1 Query OK, 1 row affected (0.00 sec) mysql> select * from tab_with_index where id = 1;

InnoDB存儲引擎使用相同索引鍵的阻塞例子 :
(3)當表有多個索引的時候,不同的事務可以使用不同的索引鎖定不同的行,另外,不論是使用主鍵索引、唯一索引或普通索引,InnoDB都會使用行鎖來對數據加鎖。
在下面的例子中,表tab_with_index的id字段有主鍵索引,name字段有普通索引:
mysql> alter table tab_with_index add index name(name); 1Query OK, 5 rows affected (0.23 sec) Records: 5 Duplicates: 0 Warnings: 0
InnoDB存儲引擎的表使用不同索引的阻塞例子 :

(4)即便在條件中使用了索引字段,但是否使用索引來檢索數據是由MySQL通過判斷不同執行計劃的代價來決 定的,如果MySQL認為全表掃描效率更高,比如對一些很小的表,它就不會使用索引,這種情況下InnoDB將使用表鎖,而不是行鎖。因此,在分析鎖沖突 時,別忘了檢查SQL的執行計劃,以確認是否真正使用了索引。
比如,在tab_with_index表里的name字段有索引,但是name字段是varchar類型的,檢索值的數據類型與索引字段不同,雖然MySQL能夠進行數據類型轉換,但卻不會使用索引,從而導致InnoDB使用表鎖。通過用explain檢查兩條SQL的執行計劃,我們可以清楚地看到了這一點。
mysql> explain select * from tab_with_index where name = 1 \G mysql> explain select * from tab_with_index where name = '1' \G
間隙鎖(Next-Key鎖)
當我們用范圍條件而不是相等條件檢索數據,并請求共享或排他鎖時,InnoDB會給符合條件的已有數據記錄的 索引項加鎖;對于鍵值在條件范圍內但并不存在的記錄,叫做“間隙(GAP)”,InnoDB也會對這個“間隙”加鎖,這種鎖機制就是所謂的間隙鎖 (Next-Key鎖)。
舉例來說,假如emp表中只有101條記錄,其empid的值分別是 1,2,…,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一個范圍條件的檢索,InnoDB不僅會對符合條件的empid值為101的記錄加鎖,也會對empid大于101(這些記錄并不存在)的“間隙”加鎖。
InnoDB使用間隙鎖的目的,一方面是為了防止幻讀,以滿足相關隔離級別的要求,對于上面的例子,要是不使 用間隙鎖,如果其他事務插入了empid大于100的任何記錄,那么本事務如果再次執行上述語句,就會發生幻讀;另外一方面,是為了滿足其恢復和復制的需 要。有關其恢復和復制對鎖機制的影響,以及不同隔離級別下InnoDB使用間隙鎖的情況,在后續的章節中會做進一步介紹。
很顯然,在使用范圍條件檢索并鎖定記錄時,InnoDB這種加鎖機制會阻塞符合條件范圍內鍵值的并發插入,這往往會造成嚴重的鎖等待。因此,在實際應用開發中,尤其是并發插入比較多的應用,我們要盡量優化業務邏輯,盡量使用相等條件來訪問更新數據,避免使用范圍條件。
還要特別說明的是,InnoDB除了通過范圍條件加鎖時使用間隙鎖外,如果使用相等條件請求給一個不存在的記錄加鎖,InnoDB也會使用間隙鎖!下面這個例子假設emp表中只有101條記錄,其empid的值分別是1,2,……,100,101。
InnoDB存儲引擎的間隙鎖阻塞例子

小結
本文重點介紹了MySQL中MyISAM表級鎖和InnoDB行級鎖的實現特點,并討論了兩種存儲引擎經常遇到的鎖問題和解決辦法。
對于MyISAM的表鎖,主要討論了以下幾點:
(1)共享讀鎖(S)之間是兼容的,但共享讀鎖(S)與排他寫鎖(X)之間,以及排他寫鎖(X)之間是互斥的,也就是說讀和寫是串行的。
(2)在一定條件下,MyISAM允許查詢和插入并發執行,我們可以利用這一點來解決應用中對同一表查詢和插入的鎖爭用問題。
(3)MyISAM默認的鎖調度機制是寫優先,這并不一定適合所有應用,用戶可以通過設置LOW_PRIORITY_UPDATES參數,或在INSERT、UPDATE、DELETE語句中指定LOW_PRIORITY選項來調節讀寫鎖的爭用。
(4)由于表鎖的鎖定粒度大,讀寫之間又是串行的,因此,如果更新操作較多,MyISAM表可能會出現嚴重的鎖等待,可以考慮采用InnoDB表來減少鎖沖突。
對于InnoDB表,本文主要討論了以下幾項內容:
(1)InnoDB的行鎖是基于索引實現的,如果不通過索引訪問數據,InnoDB會使用表鎖。
(2)介紹了InnoDB間隙鎖(Next-key)機制,以及InnoDB使用間隙鎖的原因。
在不同的隔離級別下,InnoDB的鎖機制和一致性讀策略不同。
在了解InnoDB鎖特性后,用戶可以通過設計和SQL調整等措施減少鎖沖突和死鎖,包括:
盡量使用較低的隔離級別; 精心設計索引,并盡量使用索引訪問數據,使加鎖更精確,從而減少鎖沖突的機會;選擇合理的事務大小,小事務發生鎖沖突的幾率也更小;給記錄集顯式加鎖時,最好一次性請求足夠級別的鎖。比如要修改數據的話,最好直接申請排他鎖,而不是先申請共享鎖,修改時再請求排他鎖,這樣容易產生死鎖;不同的程序訪問一組表時,應盡量約定以相同的順序訪問各表,對一個表而言,盡可能以固定的順序存取表中的行。這樣可以大大減少死鎖的機會;盡量用相等條件訪問數據,這樣可以避免間隙鎖對并發插入的影響; 不要申請超過實際需要的鎖級別;除非必須,查詢時不要顯示加鎖;對于一些特定的事務,可以使用表鎖來提高處理速度或減少死鎖的可能。
mysql鎖機制原理及用法就先給大家講到這里,對于其它相關問題大家想要了解的可以持續關注我們的行業資訊。我們的板塊內容每天都會捕捉一些行業新聞及專業知識分享給大家的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





