溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1. 工具產生的背景
導航對人們的生活起著越來越重要的作用,由于公司一直在做導航產品,所以為了從深度上保證產品的質量(已經通過大量的case從廣度上來保證產品質量),做為Routing的測試負責人,我對導航算法進行了深入的研究。
在做Map Data的Regression時,我們是基于導航對底層的數據進行測試,而MapData是經過Tools Team 轉換的,所以原始數據的改動、Tools的改動都會引起導航的變化,而這兩層對從上層測試的我們來說都是blackbox。測試時,用自動化工具找出difference很容易,但check起來相當困難,因為我們不光需要知道路線變了,而且需要知道它是怎么變的,否則你不知道你的模型是不斷優化的。當時一天也就check十幾條路線變化的case,對于五六千條case的一輪Regression,測試工作量是呈指數增長的,已經不是增加一兩個人就能解決問題的。
導航,本身就是機器學習的過程,所以用傳統的功能測試抽取case覆蓋各個feature的方法在這種情況下不是完全適用:一是因為一條規劃的路線會涉及到幾百、甚至上萬條link,每條link又有多個影響因子,如果有一個或幾個因子變化,都可能引起導航路徑的變化,更何況是這么多個可變因子,而且以前設計的覆蓋Feature的case,可能會因為數據變了就cover不到了;二是因為機器學習本身就是通過大量的數據,對原型不斷進行訓練、不斷優化的過程,所以減少case進行測試,很可能會使模型陷入局部最優。所以作為數學系的我,認為機器學習的原型用機器學習的方法測試才是最好的解決方案,于是想到了神經網絡。
在這個時期飽受折磨的不光是我們team的QA,ToolsTeam的dev也被要求用我們的Regression工具check case,要知道他們對導航的邏輯不了解,check起來難度多大(即使知道導航變了,但為什么變,你得知道)。這使我深刻意識到自動化工具的思想,比自動化工具的開發要重要得多,Tools Team的lead曾經說過一句話:只要你有想法,我們就能把工具做出來。所以經過大概兩周的折磨,在凌晨四點的睡夢中終于有了solution,而不是idea,當時那叫一個興奮啊JJ
第二天,跟mgr討論了之后,他同意了我的solution,于是找到ToolsTeam的一個牛人,僅用了幾天時間,就把工具生成出來了。
2. 人工神經網絡ANN (Artificial Neural Network)
主要類型:
· 前向神經網絡
· 反饋網絡
· 自組織網絡
· 相互結合型網絡
為了使模型相對簡單、準確,我們采用三層前向神經網絡(即含一個隱含層)
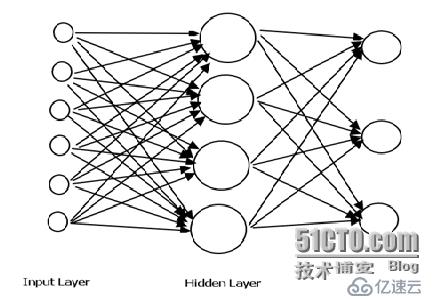
3. 實現的思想
· 抽取difference
采用第三方工具(diff.exe)將新舊地圖的difference進行對比(類似Beyond Compare的功能)并且輸出。
· 使用神經網絡模型
輸入層:diff.exe的output。
隱含層:內部處理邏輯
輸出層:分類的結果和變化的cost
輸入層到隱含層的權重:w(ih)
隱含層到輸出層的權重:w(ho)
· 實現分類
根據feature 進行分類,通過config.xml手動配置來定義分類的優先級:
· 計算從輸入層到隱含層的權重w(ih)
將priority 轉換成 [0, 1]之間的數(當時就卡在了這個轉換過程上,想到了神經網絡,但就是不知道怎么將現有的輸入和期望的輸出轉換成數學模型):
F1 = (1/2)^1
F2= (1/2)^2
F3 =(1/2)^3
F4 = (1/2)^4
F5 =(1/2)^5
F6 = (1/2)^6
F7=(1/2)^7
…
Notes:
1) Fn: 代表第n個feature
2) 根據等比數列1/2^n 給每個分類因素定義權重,這樣做的目的是為了使每個weight最后加起來的值無限接近但<1,即使所有的expectedresult 全變化了,最大值不會超過1
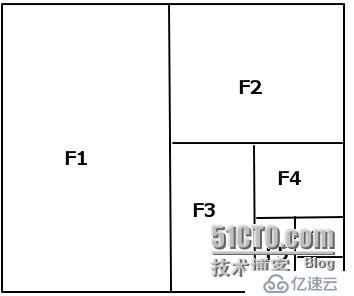
3)分類的順序可以根據每次的改動調整
4)Config.xml的格式可修改為:
<priority>
<pr name="F1"value=1/>
<pr name="F2"value=2/>
<pr name="F3" value=3/>
<pr name="F4"value=4/>
<prname="F5"value=5/>
<pr name="F6" value=6/>
<pr name="F7" value=7/>
…
<pr name="Fn" value=0/>
</priority>
因此每個分類的weight=(1/2)^value
(對于不需要check的difference,不用計算,value設為0)
4. 定義隱含層到輸出層的權重w(ho):
對于每個feature,可能不止一處發生變化,根據經驗,設置可能變化的最大個數(config.xml里配置,可手動修改)
Config.xml可定義為
<hidden_output>
<f1weight="1/5"/>
<f3 weight="1/10"/>
<f4weight ="1/3"/>
<f5weight="1/10"/>
…
</hidden_output >
· 由于之前把主要的精力放到了check路線變化的case上,既慢又發現不了什么問題,后來經過經驗和簡單利用了下統計的原理,證明了引起長路徑的變化的主要因子是路的等級和速度(通常這兩個因子會引起一些列link都變),所以根據路線變化的段數計算cost,而非長路徑導航。
· 這里比較麻煩的地方是Maneuver,因為每個Maneuver的提示(左轉、右轉、上高速等等)還有另外一整套邏輯,是分類工具比較復雜的地方。
· 權重的計算思想為:通過對Tools調研,知道Tools對哪些屬性進行了處理(因為Tools的復雜度較高,了解詳細的邏輯cost非常大,所以只是通過代碼復雜度和邏輯復雜度知道個大概的情況)。根據line by line的讀導航的 code,知道Maneuver的產生條件,并計算出Tools處理過的屬性占每個maneuver的cost;根據Tools的代碼復雜度和邏輯復雜度(復雜度越高,bug可能越多)以及客戶(Customer bug is very important)報的bug類型,計算出每類maneuver的cost, 根據這兩個cost,計算出Tools的影響和客戶發現的bug占每個maneuver的cost;最后進行歸一化處理。即:從導航的邏輯、客戶、Tools的改動,以及最后的表現形式上計算cost。
· config.xml可定義為:
<all_maneuvers>
<amname="NC." weight=0.XX/>
<amname="CO." weight=0.XX/>
<amname="KP." weight=0.XX/>
<amname="KP.L" weight=0.XX/>
…
</all_maneuvers>
5. 計算從輸入層到輸出層的cost:
· F1: cost = w(ih)(F1)*(1/2+n*w(ho)(F1))=(1/2)^1*(1/2+1/2*n*1/5)
· F2: cost = w(ih)(F2)*(1/2+each w(ho)(F2))=(1/2)^2*(1/2+ 1/2*each maneuver weightfrom hidden layer to output layer)
· F3: cost = w(ih)(F3)*(1/2+n*w(ho)(F3))=(1/2)^3*(1/2+1/2*n*1/10)
· F4: cost = w(ih)( F4)*(1/2+n*w(ho)( F4))=(1/2)^4*(1/2+1/2*n*1/3)
· Fm: cost = w(ih)( Fm)*(1/2+n*w(ho)( Fm))=(1/2)^9*(1/2+1/2*n*1/30)
(n 代表每類feature的變化數量)
Notes:
1) 由此可見,F1的取值范圍應該是[1/4, 1/2],F2的取值范圍是[1/8, 1/4], F3的取值范圍是[1/16, 1/8], …
2) 由于一條case里,可能既含有F1的,又含有F2, 所以F1的權重應該在[1/4,1],同理類推F2分類里權重的總和應該在[1/8, 1/2],,…(在已經正確分類的基礎上,即使F2的cost比F1的大,也不會影響case的選取)
6. 用聚類分析方法根據最終的cost大小抽取指定數量的case。
7. 優點:
1. 在不減少Test Scope的情況下,可以合理的抽取case;在有限的時間內,check變化最大的case。
2. 通過了解Tools的改動,手動配置測試范圍和優先級,來保證產品質量。
3. 由于人工check結果時會把difference里的所有變化全check,所以此工具也是在模擬人的操作。
8. 缺點:
1.由于Case的output是基于Maneuver的,而非Routing,所以計算時存在分類錯誤,但考慮到改動開發的code cost比較高,只能根據現有的結果和經驗進行優化。
2.神經網絡本身可能陷入局部最優,所以即使權重調整再大,期望結果也可能會很小。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





