溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
目前在系統中涉及到搜索的解決方案都是通過數據庫自帶特性解決,如通過mysql5.7自帶的全文檢索功能實現資源的搜索。
這樣實現的好處是方便,無需額外開發和維護成本。但是隨著業務的發展和數據的增加,性能和可擴展方面很容易出現瓶頸。
結合本次方案庫需求的契機,決定引入spring boot + solr 為主要架構基礎的前置平臺用于應對日漸旺盛的搜索服務需求。
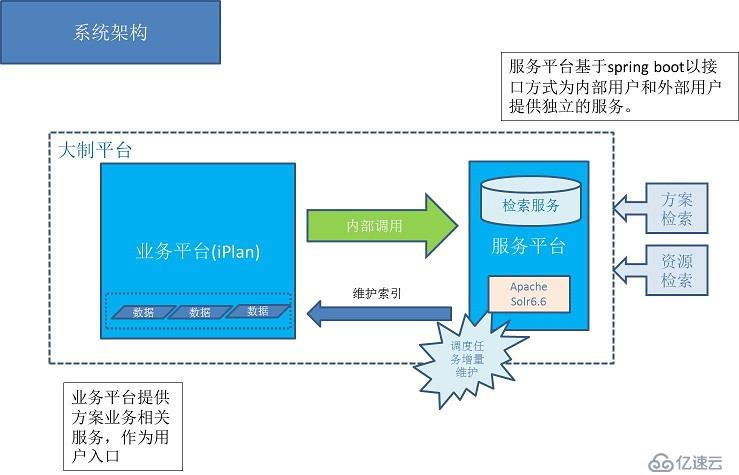
前置平臺基于spring boot開發,主要看中spring boot的微服務思想,方便開發和部署。同時可以為以后的微服務架構做技術熱身。
通過spring boot搭建的前置平臺會處理請求接入,限流,監控,安全等非功能性需求。
搜索端結合了最新的apache solr服務器端(6.6版本),使用自帶的smart-cn中文分詞組件,提供搜索服務的基礎支持。
架構實現部分主要通過具體實踐來驗證架構的可行性,不涉及具體業務細節和實際數據,
架構實現的操作描述力求做到可復制。
首先確保本機安裝了jdk8+,然后就進入eclipse,創建一個maven project。
POM文件包含以下內容:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.BUILD-SNAPSHOT</version>
</parent>
<properties>
<spring.data.solr.version>2.1.1.RELEASE</spring.data.solr.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
<version>${spring.data.solr.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
</dependency>
</dependencies>Maven結構搭好后就是搭建你的項目架構,如圖:
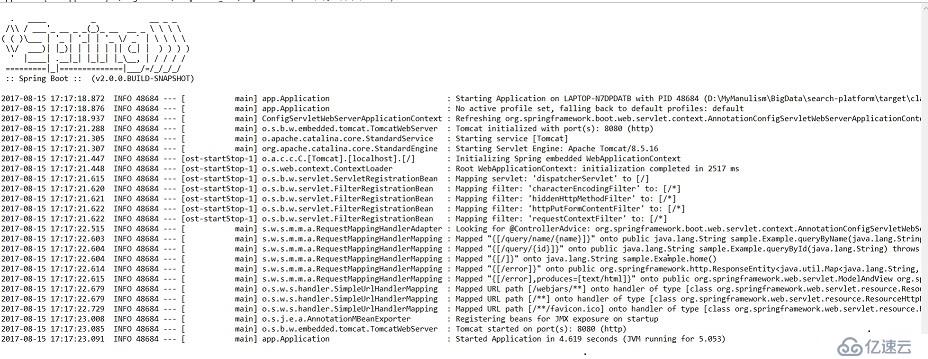
Application.java 對應了項目的入口,通過一段很簡單的代碼就可以啟動一個jetty服務了。
package app;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import sample.Example;
@SpringBootApplication
public class Application {
public static void main(String[] args) throws Exception {
SpringApplication.run(Example.class, args);
}
}運行示意圖:
首先到官方網站下載最新的安裝包,當前版本是6.6,下載zip包就可以了。
解壓后的文件夾有以下幾個目錄是首先需要關注的:
bin: 啟動腳本目錄,通過這里面的命令來啟動關閉服務器
server:solr服務器目錄,配置文件和jar包以及索引數據都是在這個目錄里面的
contrib:這個里面放的是隨版本發布的一些可選包,我們后面用到的中文分詞包就在里面
由于我們是驗證架構所以所有的配置都是基于單機的。
下一步要做的是創建一個core,在solr-6.6.0\server\solr目錄下新建一個文件夾sample_solr,包含如下文件夾
conf 配置文件目錄,初始版本從solr-6.6.0\example\example-DIH\solr\db\conf 復制
data 數據文件目錄,手工創建
core.properties 手工創建目錄,內容如下:
name=sample_solr |
創建完成core后需要修改一下core里面的配置文件,
在solr-6.6.0\server\solr\sample_solr\conf目錄下面,有三個文件,按照順序修改
solrconfig.xml
找到data import的request handler修改為
<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <str name="config">solr-data-config.xml</str> </lst> </requestHandler>
solr-data-config.xml
通過這個文件來配置你的data source和文檔字段,下面是我的配置
有幾個地方需要注意的,
batchSize
官方文檔建議針對mysql數據庫使用-1來迫使mysql使用Integer.MIN_VALUE作為fetch size,實際操作中設置成-1時我使用mysql-connector-java-5.1.24(這個驅動如果沒有需要自行下載并發到solr-6.6.0\server\lib目錄)作為驅動會出現result set close的錯誤,所以這邊設置成10,具體有沒有用還待驗證
后來在mysql的bug list找到了一個相似的問題,供參考
https://bugs.mysql.com/bug.php?id=83027
entity的PK
在deltaQuery的時候會用到,雖然deltaQuery的語句是通過update_time> xxx來獲取增量數據,實際最后查詢的時候還是通過pk in (ids) 這樣的方式,所以如果需要用到deltaQuery,PK需要設置成數據庫表的主鍵
field的定義
這邊可以看到我定義了一個tag字段,可是當你去搜索的時候,結果里面死活只出現id和name。
最后發現文檔中的字段都是要通過定義的,只不過solr為自己的sample預留了一些字段定義剛好包含id和name,這也算是個相當坑的地方。
managed-schema
上面說倒field需要通過定義,那么這個文件就是用來定義文檔中使用到的字段和字段類型了。Solr正是通過scheme定義來構建索引。
這個scheme文件包含四種元素:
field type
字段的類型如文本,數字浮點等,定義貼切的類型有利于solr更準確的識別字段并輸出結果
field
字段,用于組成solr文檔的的基本單位。如果從面向對象角度來看,一個文檔是一個對象,相應的字段就是這個對象的屬性
dynamicField
動態字段,solr除了提供一些默認字段之外還預留了一些通配符字段定義,如下:
<dynamicField name="*_txt" type="text_general" multiValued="true" indexed="true" stored="true"/> |
結合我們上面的tag字段,如果我們覺得每個字段都要定義太麻煩,那么可以在entity里面直接使用dynamic field,
<field column="tag" name="tag_txt" type="string"/> |
重新建立索引后,我們的搜索結果如圖:
copyField
從名字就可以看出來這是一個復制字段功能,從定義來看也很明顯的發現有source有dest。一個主要的用途就是全文檢索,將需要檢索的字段都copy到一個字段,之后對這個字段的搜索不就是全文檢索了嗎?這個和早期數據庫里面將幾個字段組合起來后來個模糊查詢就是全文搜索是一個道理。
這個要注意的是如果source有幾個字段,那么目標字段的multiValued需要設置為true
更詳細的含義建議參考官方文檔,我們主要涉及field type,field和copyField的定義,這里就基于我們的例子來看看。
field type在一般情況下不需要擴展,因為solr已經自帶了很多的類型了,這里我們為了支持中文分詞,新增一個字段類型如下
<fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.HMMChineseTokenizerFactory"/> <filter class="solr.CJKWidthFilterFactory"/> <filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt"/> <filter class="solr.PorterStemFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.HMMChineseTokenizerFactory"/> <filter class="solr.CJKWidthFilterFactory"/> <filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt"/> <filter class="solr.PorterStemFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
可以看出一個field type由兩部分構成,index和query。Index負責建立索引的時候對于字段的解析而query負責查詢的時候。同時為了中文分詞我們需要從solr-6.6.0\contrib\analysis-extras\lucene-libs中拷貝lucene-analyzers-smartcn-6.6.0.jar這個jar包到webapp\WEB-INF\lib
field的配置如下:
1 | <field name="tag" type="text_smart" indexed="true" stored="true"/><field name="text" type="text_smart" multiValued="true" indexed="true" stored="false"/> |
主要是對需要支持中文的字段type配置成我們之前定義的text_smart
copyField
<copyField source="name" dest="text"/><copyField source="tag" dest="text"/> |
通過上面的配置我們一個solr服務器端就可以正常運作了,我們回顧一下我們的過程
最后我們進入命令行,通過solr.cmd start來啟動
基于我們前面兩個章節的內容,這時候要做的就是在spring boot項目里面提供solr服務器的搜索接口封裝以及索引的維護。
首先我們需要創建solr的配置,通過兩個文件
1, application.properties
在src/main/resource目錄下面新建一個properties文件,內容如下
spring.data.solr.host=http://127.0.0.1:8983/solr/sample_solr |
2, SolrConfig.java
通過注解將properties中定義的屬性注入到bean中
package sample;
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = "spring.data.solr")
public class SolrConfig {
private String host;
private String zkHost;
private String defaultCollection;
//getter setter
}接下來就是通過一個controller來通過restful的方式將用戶接口和solr script連接起來。
下面是我們的一個查詢controller
package sample;
//import section
@RestController
@EnableAutoConfiguration
public class Example {
@Autowired
private SolrClient client;
@RequestMapping("/query/name/{name}")
public String queryByName(@PathVariable String name) throws IOException, SolrServerException {
ModifiableSolrParams params =new ModifiableSolrParams();
params.add("q",name);
params.add("hl","on");
params.add("hl.fl","name,tag");
params.add("ws","json");
params.add("start","0");
params.add("rows","10");
QueryResponse response=null;
try{
response=client.query(params);
SolrDocumentList results = response.getResults();
for (SolrDocument document:results) {
System.out.println( document);
}
}catch(Exception e){
e.getStackTrace();
}
return response.toString();
}
}啟動spring boot服務,在瀏覽器輸入我們的查詢指令后就可以得到結果了
http://localhost:8080/query/name/測試
通過架構實現部分的驗證,基于spring boot + solr的前置服務架構是可行的。但是作為一個前置平臺來說,我們還需要關注哪些點呢?
安全性
前置平臺很多時候是暴露在通用防火墻之外的,所以危險系數往往也是很高的。我們主要從兩個方面來加強防范
限流
通過限流和適當的服務降級,保證服務可用性以及避免可能的流量***。具體實施可以參照線程池的思想,不具體展開。
認證
通過認證體系結合加密算法保證信息傳輸的保密性和完整性
可靠性
可靠性是指系統的可用程度,涵蓋系統持續運行時間,宕機時間,服務回復時間等因素。我們通過預防和監控兩個途徑來保證。
預防
通過部署集群服務從前置,搜索服務角度去除單點
監控
通過獨立的監控系統對前置系統和搜索服務器進行監控,設定合理的閾值和報警點
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





