溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
原本以為,Spring 通過解析 bean 的配置,生成并注冊 bean defintions 的過程不太復雜,比較簡單,不用單獨開辟一篇博文來講述;但是當在分析前面兩個章節有關 @Autowired、@Component、@Service 注解的注入機制的時候,發現,如果沒有對有關 bean defintions 的解析和注冊機制徹底弄明白,則很難弄清楚 annotation 在 Spring 容器中的底層運行機制;所以,本篇博文作者將試圖去弄清楚 Spring 容器內部是如何去解析 bean 配置并生成和注冊 bean definitions 的相關主流程;
備注,本文是作者的原創作品,轉載請注明出處。
? bean definitions 是什么?
其實很簡單,就是 Java 中的 POJO,用來描述 bean 配置中的 element 元素的,比如,我們有如下的一個簡單的配置
beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="org.shangyang" />
<bean name="jane" class="org.shangyang.spring.container.Person">
<property name="name" value="Jane Doe"/>
</bean>
</beans> 可以看到,上面有三個 element
在配置文件 beans.xml 被 Spring 解析的過程中,每一個 element 將會被解析為一個 bean definition 對象緩存在 Spring 容器中;
? 需要被描述為 bean definitions 的配置對象主要分為如下幾大類,
? 最開始我的確是這么認識 bean definitions 的,但是當我分析完有關 bean definitions 的相關邏輯和源碼以后,對其認識有了升華,參考寫在最后;
最好的分析源碼的方式,就是通過高屋建瓴,逐個擊破的方式;首先通過流程圖獲得它的藍圖(頂層設計圖),然后再根據藍圖上的點逐個擊破;最后才能達到融會貫通,胸有成竹的境界;所以,這里作者用這樣的方式帶你深入剖析 Spring 容器里面的核心點,以及相關主流程到底是如何運作的。
為了一次性把上述源碼分析所描述有的情況闡述清楚,我們繼續使用 Spring Core Container 源碼分析六:@Service 中使用的測試用例;唯一做的修改是,再使用一個特殊的 element xmlns:p 來配置 john,這樣可以進一步去調試自定義 Spring 配置標簽是如何實現的;
beans.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="org.shangyang" />
<bean name="john"
class="org.shangyang.spring.container.Person"
p:name="John Doe"
p:spouse-ref="jane"/>
<bean name="jane" class="org.shangyang.spring.container.Person">
<property name="name" value="Jane Doe"/>
</bean>
<bean name="niba" class="org.shangyang.spring.container.Dog">
<property name="name" value="Niba" />
</bean>
</beans>整個流程是從解析 bean definitions 流程開始的,對應的入口是主流程的 step 1.1.1.2 obtainFreshBeanFactory;
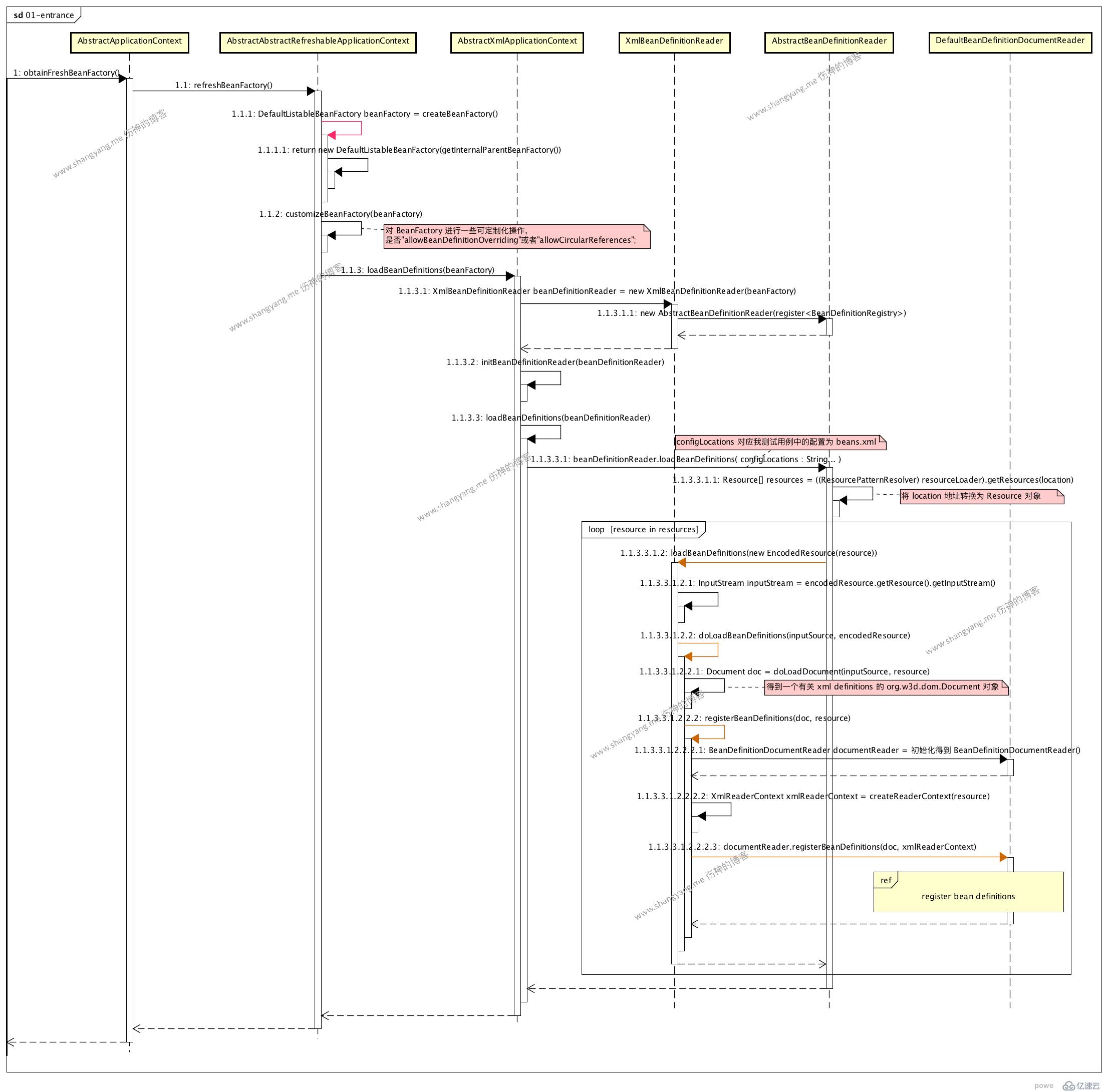
首選初始化得到 BeanFactory 實例 DefaultListableBeanFactory,用來注冊解析配置后生成的 bean definitions;
然后通過 XmlBeanDefinitionReader 解析 Spring XML 配置文件
根據用戶指定的 XML 文件路徑 location,進行解析并且得到 Resource[] 對象,具體參考 step 1.1.3.3.1.1 getResource(location) 步驟;這里,對其如何通過 location 得到 Resource[] 對象做進一步分析,看源碼,
PathMatchingResourcePatternResolver.java
public Resource[] getResources(String locationPattern) throws IOException {
Assert.notNull(locationPattern, "Location pattern must not be null");
if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {
// a class path resource (multiple resources for same name possible)
if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {
// a class path resource pattern
return findPathMatchingResources(locationPattern);
}
else {
// all class path resources with the given name
return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));
}
}
else {
// Only look for a pattern after a prefix here
// (to not get fooled by a pattern symbol in a strange prefix).
int prefixEnd = locationPattern.indexOf(":") + 1;
if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {
// a file pattern
return findPathMatchingResources(locationPattern);
}
else {
// a single resource with the given name
return new Resource[] {getResourceLoader().getResource(locationPattern)};
}
}
} 這里的解析過程主要分為兩種情況進行解析,一種是前綴是 classpath: 的情況,一種是普通的情況,正如我們當前所使用的測試用例的情況,既是 new ClassPathXmlApplicationContext("beans.xml") 的情況,這里不打算在這里繼續深挖;
當完成上述三個步驟以后,將進入 register bean definitions process 流程
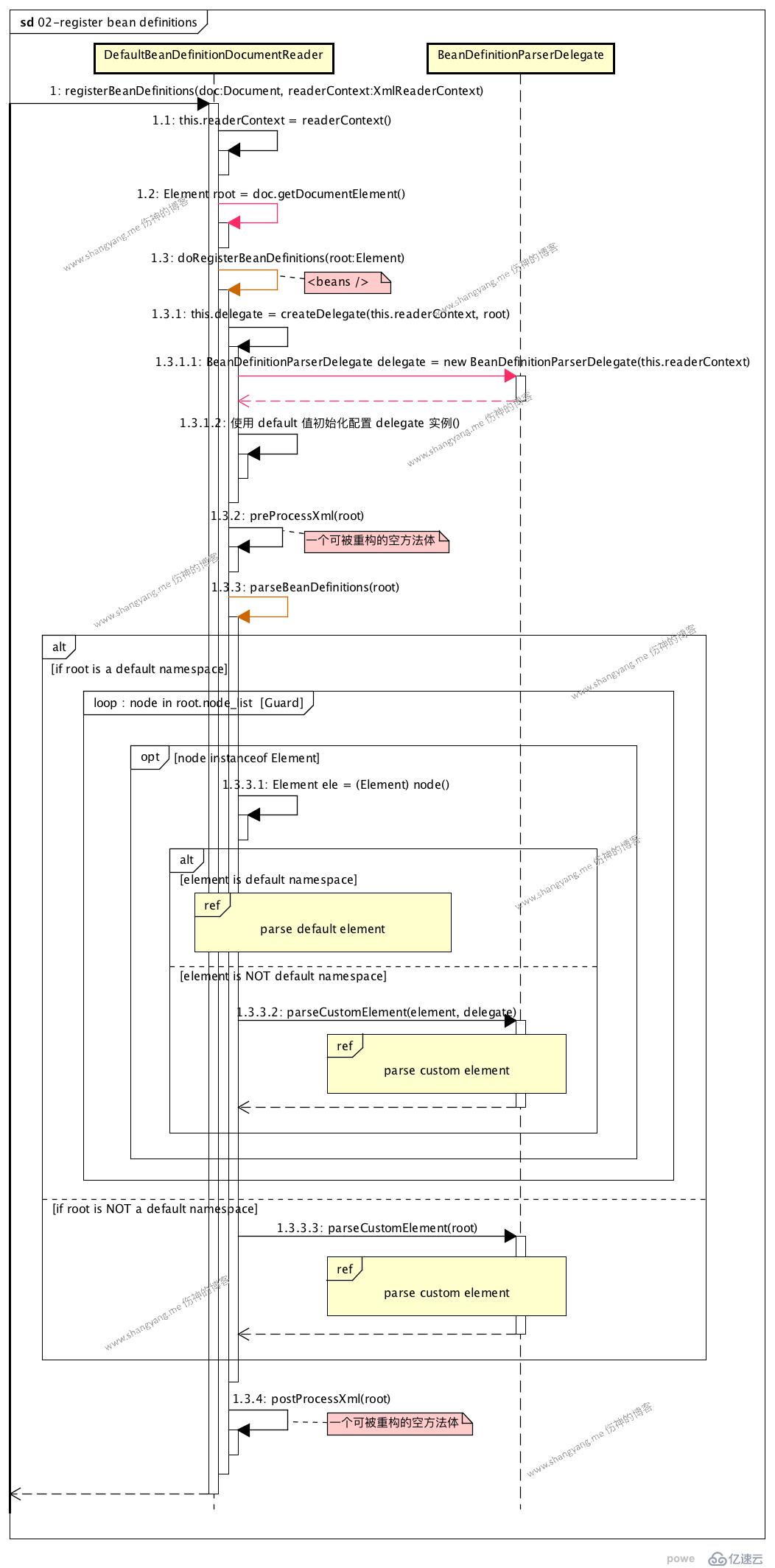
? 首先,重要的兩件事情是,
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
</beans>就是一個 xml 配置文件中的最頂層元素 <beans/>
? 后續,當前面的工作準備好了以后,來看看是如何解析 element 的?
首先,判斷 root 元素的 namespace 對應的是不是 default namespace,若不是,將進入 step 1.3.3.3: parse custom element;這里我們關注常規流程,既是當 root 元素的 namespace 是 default namespace 的流程;
遍歷 root 元素下的所有 element,
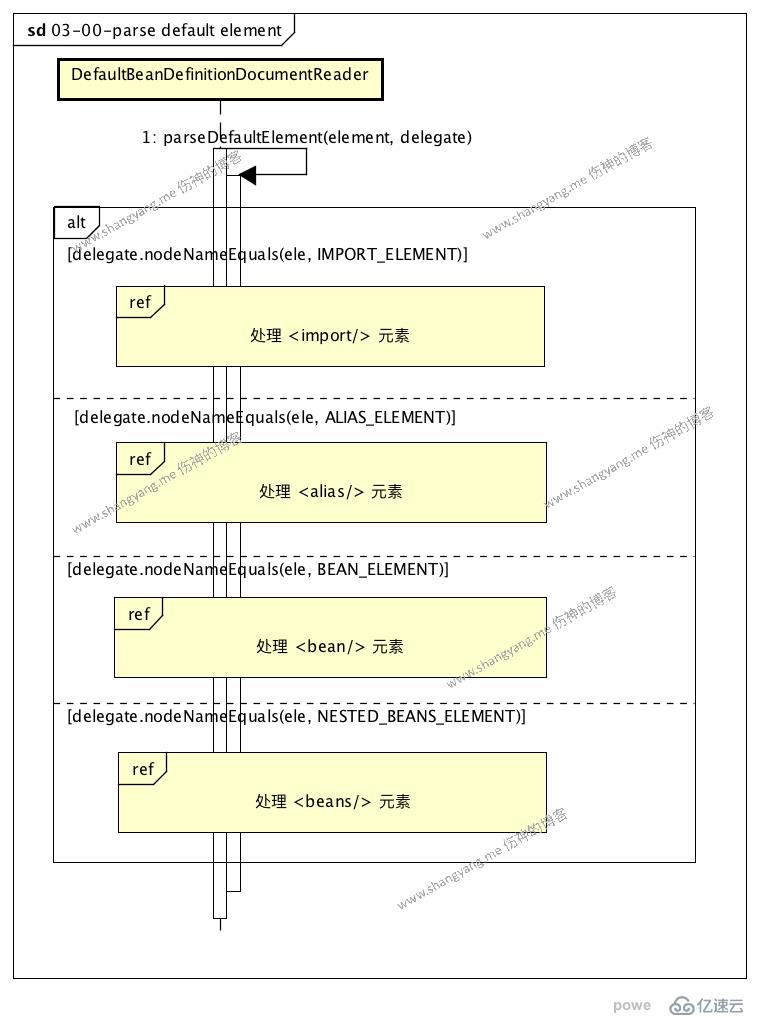
可以看到,該流程中包含四個子流程,依次處理不同的 element 元素的情況,其它三種都是比較特殊的情況,我們這里,主要關注“解析 <bean/>" 元素的流程”
這里,為了能夠盡量的展示出解析 <bean/> 元素的流程中的邏輯,我將使用一個比較特殊的 <bean/> 來梳理此部分的流程;
<bean name="john"
class="com.example.Person"
p:name="John Doe"
p:spouse-ref="jane"/>該 <bean/> 元素使用了 namespace xmlns:p="http://www.springframework.org/schema/p"
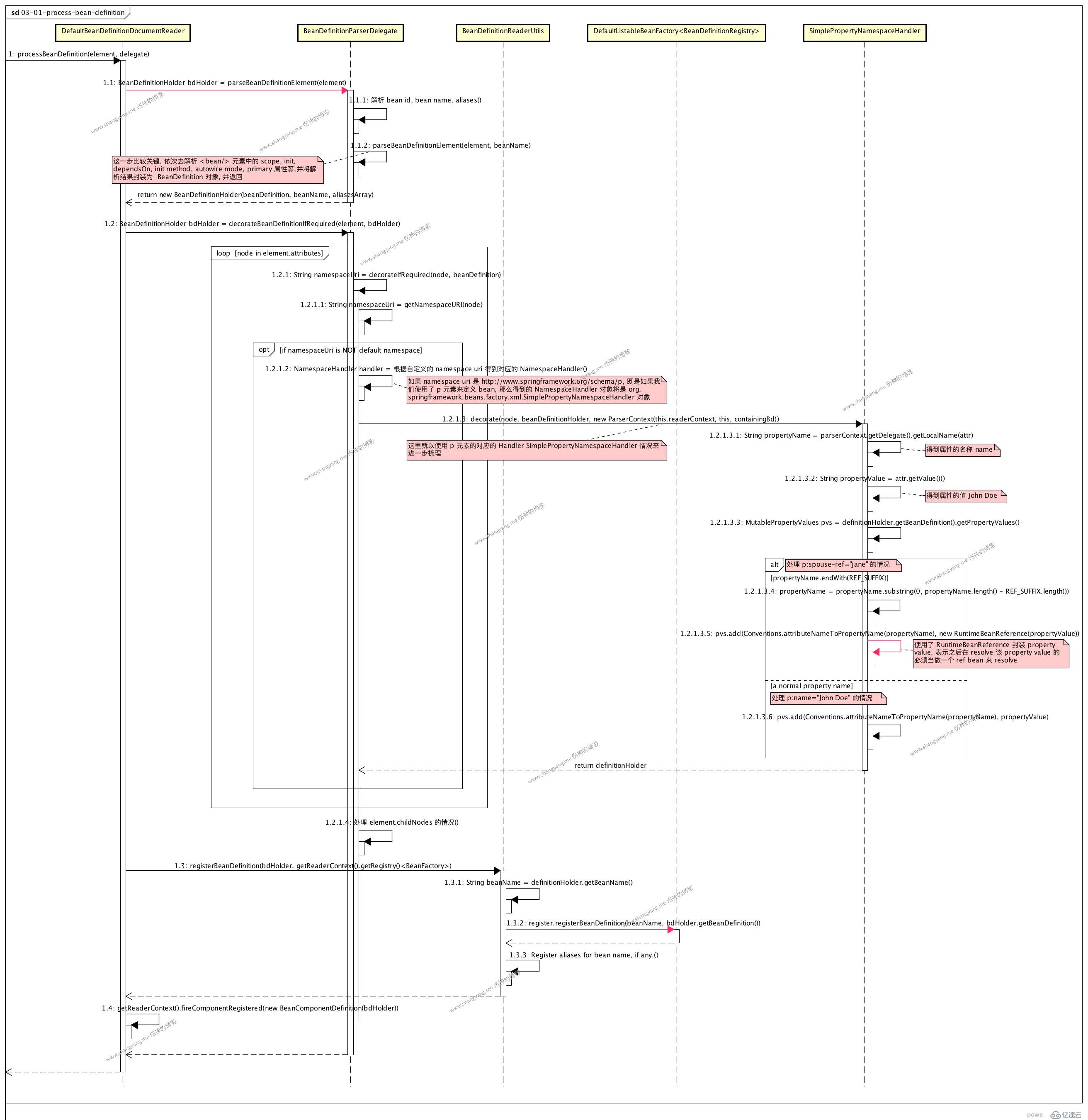
? 首先,通過 BeanDefintionParserDelegate 對象解析該 element,得到一個 BeanDefinitionHolder 對象 bdHolder 實例;該解析過程中會依次去解析 bean id, bean name, 以及相關的 scope, init, autowired model 等等屬性;見 step 1.1
? 其次,對 bean definition 進行相關的修飾操作,見 step 1.2
常規步驟
attribute node 的修飾過程
假設,我們當前的 attribute node 為 p:spouse-ref="jane",看看該屬性是如何被解析的,
首先,通過 node namespace 得到對應的 NamespaceHandler 實例 handler
通過 xmlns:p="http://www.springframework.org/schema/p" 得到的 NamespaceHandler 為 SimplePropertyNamespaceHandler 對象;
其次,調用 SimplePropertyNamespaceHandler 對象對當前的元素進行解析;
可以看到,前面的解析并沒有什么特殊的,從元素 p:spouse-ref="jane" 中解析得到 propery name: spouse-ref,property value: jane;但是后續解析,比較特殊,需要處理 REF_SUFFIX 的情況了,也就是當 property name 的后綴為 -ref 的情況,表示該 attribute 是一個 ref-bean 屬性,其屬性值引用的是其它的 bean 實例,所以呢,這里將其 property value 封裝為了一個 RuntimeBeanReference 對象實例,表示將來在解析該 property value 為 Java Object 的時候,需要去初始化其引用的 bean 實例 jane,然后注入到當前的 property value 中;
? 最后,注冊 bean definition;
見 step 1.3.2 register.registerBeanDefinition(beanName, beanDefinition),register 就是當前的 bean factory 實例,通過將 bean name 和 bean definition 以鍵值對的方式在當前的 bean factory 中進行注冊;這樣,我們就可以通過 bean 的名字,得到其對應的 bean definition 對象了;
? 寫在該小節最后,
我們也可以自定義某個 element 或者 element attribute,并且定義與之相關的 namespace 和 namespace handler,這樣,就可以使得 Spring 容器解析自定義的元素;類似于 dubbo 配置中所使用的 <dubbo /> 自定義元素那樣;
此步驟對應 register bean definitions process 步驟中的 step 1.3.3.2
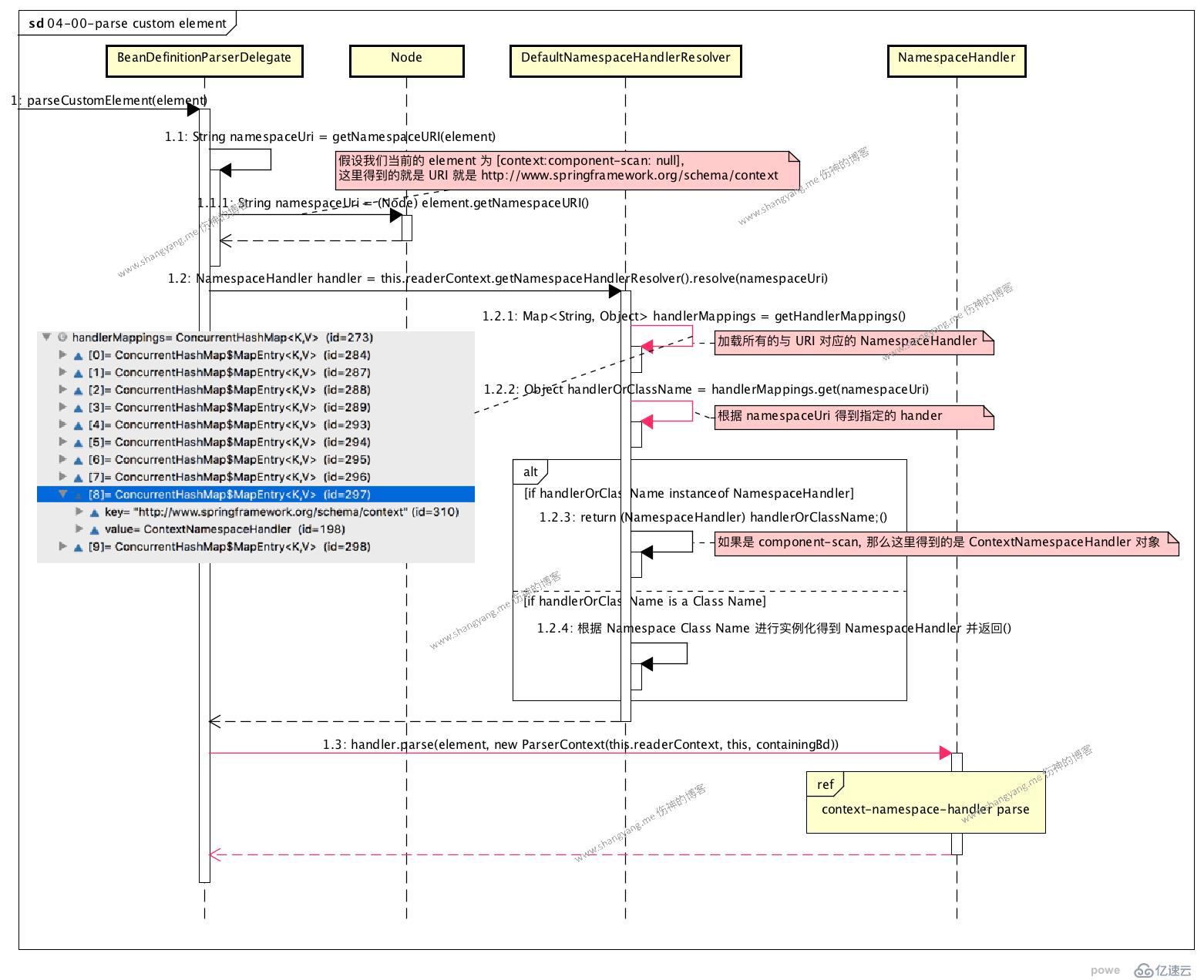
該小節我將試圖使用一個常用的 custom element: <context:component-scan/> 來梳理整個流程;
繼續 parse custom element process 章節中所使用到的例子,<context:component-scan/> 來分析該流程,

? 在開始分析之前,看看 component-scan 元素長什么樣,
注意,component-scan element 本身包含 annotation-config attribute;
? 流程分析
首先,根據 element name: component-scan 找到對應的 BeanDefinitionParser,在 ContextNamespaceHandler 初始化的時候,便初始化設置好 8 對內置的 element name 與 parsers 的鍵值對;這里,根據名字 component-scan 找到對應的 parser ComponentScanBeanDefinitionParser 對象;
其次,使用 ComponentScanBeanDefinitionParser 對象開始解析工作,
首先,解析 <context:component-scan base-package="org.shangyang"/> 得到 basePcakges String[] 對象;
其次,初始化得到 ClassPathBeanDefinitiionScanner 對象實例 scanner,然后調用 scanner.doScan 方法進入 [do scan 流程](#do-scan 流程),該流程中將會遍歷 base package 中所包含的所有 .class 文件,解析之,并生成相應的 bean definitions;另外在這個流程中,還要注意的是,最后會將 bean definitions 在當前的 bean factory 對象中進行注冊;
這里主要介紹上一個小節中 #2 步驟中所提到的 do scan 流程步驟,對應 parse element by ContextNamespaceHandler 流程圖中的 step 1.2.3 scanner.doScan;
? 先來看看 step 1.2.3.1 findCandidateComponent(basePackage)
ClassPathScanningCandidateComponentProvider.java (已刪除大量不相干代碼)
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<BeanDefinition>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
//1. 從當前用戶自定的 classpath 子路徑中,通過 regex 查詢到所有的所匹配的 resources;要特別注意的是,
// 這里為什么不直接通過 Class Loader 去獲取 classes 來進行判斷? 因為這樣的話就相當于是加載了 Class Type,而 Class Type 的加載過程是通過 Spring 容器嚴格控制的,是不允許隨隨便便加載的
// 所以,取而代之,使用一個 File Resource 去讀取相關的字節碼,從字節碼中去解析........
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
//2. 依次遍歷用戶定義的 bean Class 對象
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
// 將從字節碼中獲取到的相關 annotation(@Service) 以及 FileSystemResource 對象保存在 metadataReader 當中;
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
candidates.add(sbd);
}
...
}
...
}
...
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
代碼第 10 行
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath); 這一步通過遞歸搜索 base package 目錄下的所有 .class 文件,并將其字節碼封裝成 Resource[] 對象;上面的注釋解釋得非常清楚了,這里封裝的是 .class 文件的字節碼,而非 class type;除了注解中所描述的,這里再引申說明下,這里為什么不直接加載其 Class Type 還有一個原因就是當 Spring 在加載 Class Type 的時候,很有可能在該 Class Type 上配置了 AOP,通過 ASM 字節碼技術去修改原有的字節碼以后,再加入 Class Loader 中;所以,之類不能直接去解析 Class Type,而只能通過字節碼的方式去解析;
這一步同樣告誡我們,在使用 Spring 容器來開發應用的時候,開發者不要隨隨便便的自行加載 Class Type 到容器中,因為有可能在加載 Class Type 之前需要通過 Spring 容器的 ASM AOP 進行字節碼的修改以后再加載;
代碼第 23 行
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);解析當前的 .class 字節碼,解析出對應的 annotation,比如 @Service,并將其協同 FileSystemResource 對象一同保存到 metadataReader 對象中;
代碼第 24 行
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) { // includedFilters 包含三類 annotation,1. @Component 2. @ManagedBean 3. @Named
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return isConditionMatch(metadataReader);
}
}
return false;
} 既是從當前的 metadataReader 中去判斷是否存在 1. @Component 2. @ManagedBean 3. @Named 三種注解中的一種,如果是,則進入下面的流程
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
candidates.add(sbd);
}
...
}? 依次處理并注冊返回的 candidates
該步驟從流程圖 parse element by ContextNamespaceHandler 中的 step 1.2.3.2 開始,主要做了如下幾件事情,
/**
* 因為通過 @Component、@Serivce 等注解的方式不會像 xml-based 配置那樣提供了一個 name 的標簽,可以指定 bean name;所以,這里需要去單獨為其生成一個;
*/
@Override
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
if (definition instanceof AnnotatedBeanDefinition) {
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition); // 處理諸如 @Service("dogService") 的情況
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
// Fallback: generate a unique default bean name. 里面的實現邏輯就是通過將 Class Name 的首字母大寫編程小寫,然后返回;
return buildDefaultBeanName(definition, registry);
} 通常情況下,是將類名的首字母進行小寫并返回;對應 step 1.2.2.3.3
該步驟從流程圖 parse element by ContextNamespaceHandler 的 step 1.2.4.2 registerAnnotationConfigProcessors 開始,將會依次注冊由如下 post-processor class 對象所對應的 post-processor-bean-definitions,
注意,這里都是通過 Class 對象注冊的,并非注冊的實例化對象,下面,我們來簡單分析一下注冊相關的源碼,以注冊 AutowiredAnnotationBeanPostProcessor post-processor-bean-definition 為例子,
AnnotationConfigUtils#registerAnnotationConfigProcessors
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
// 將 AutowiredAnnotationBeanPostProcessor.class 封裝為 bean definition
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}上面的步驟將 AutowiredAnnotationBeanPostProcessor.class 封裝為 bean definition;
AnnotationConfigUtils.registerPostProcessor
private static BeanDefinitionHolder registerPostProcessor(
BeanDefinitionRegistry registry, RootBeanDefinition definition, String beanName) {
definition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(beanName, definition); // 注冊 bean definition
return new BeanDefinitionHolder(definition, beanName);
}這一步將 AutowiredAnnotationBeanPostProcessor 所對應的 bean definition 注入了當前的 bean factory 當中;
AutowiredAnnotationBeanPostProcessor 提供了 @Autowired 注解注入機制的實現,詳情參考 AutowiredAnnotationBeanPostProcessor 章節;
通過上述的分析,可以清晰的看到,bean definition 的作用是什么,就是通過 bean definition 中的描述去限定通過 Class Type 實例化得到 instance 的業務規則,我們看看由 do scan 流程 所生成的 annotation-bean-definition<ScannedGenericBeanDefinition> 對象,
{% asset_img debug-scanned-generic-bean-definition.png %}
可以看到,當我們在后續要根據該 annotation-bean-definition 得到一個 DogService 實例的時候,所要遵循的業務規則,如下所示,
Generic bean: class [org.shangyang.spring.container.DogService];
scope=;
abstract=false;
lazyInit=false;
autowireMode=0;
dependencyCheck=0;
autowireCandidate=true;
primary=false;
factoryBeanName=null;
factoryMethodName=null;
initMethodName=null;
destroyMethodName=null;
defined in file [/Users/mac/workspace/spring/framework/sourcecode-analysis/spring-core-container/spring-sourcecode-test/target/classes/org/shangyang/spring/container/DogService.class]不過,要注意,這里所得到的 ScannedGenericBeanDefinition 實例,同樣沒有真正去加載 org.shangyang.spring.container.DogService Class Type 到容器中,而只是將 class name 字符串賦值給了 ScannedGenericBeanDefinition.beanClass,言外之意,將來在加載 Class Type 到容器中的時候,或許與實例化 instance 一樣也要根據 bean definitions 中的規則來限定其加載行為,目前我所能夠想到的與其相關的就是 ASM 字節碼技術,可以在 bean definition 中定義 ASM 字節碼修改規則,來控制相關 Class Type 的加載行為;
本文轉載自本人的私人博客,傷神的博客 http://www.shangyang.me/2017/04/07/spring-core-container-sourcecode-analysis-register-bean-definitions/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





