溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們在之前實現了單鏈表,那么我們如何遍歷單鏈表中的每一個數據元素呢?肯定直接一個 for 循環就可以搞定啊,我們來看看當前基于我們實現的單鏈表遍歷的方法,main.cpp 如下
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++) // O(1)
{
list.insert(0, i);
}
for(int i=0; i<list.length(); i++) // O(n)
{
cout << list.get(i) << endl;
}
return 0;
}我們來看看輸出結果,看看是不是遍歷呢
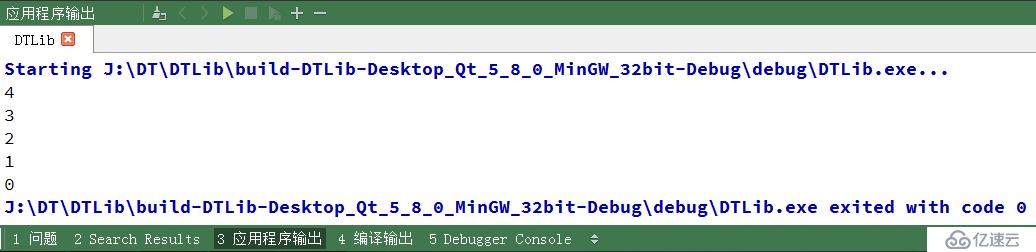
結果是正確的,我們來分析下上面的測試代碼的效率。第一個 for 循環,因為每次都是在 0 位置處插入數據元素,因此它的時間復雜度是 O(1);而第二個 for 循環,因為它要全部循環一遍,因此它的時間復雜度為 O(n)。我們就奇怪了,明明同樣是兩個 for 循環,效率竟然不相同。不能以線性的時間復雜度完成單鏈表的遍歷,那么此時新的需求就產生了:為單鏈表提供新的方法,在線性時間內完成遍歷。
下來說說設計思路,利用游標的思想:
1、在單鏈表的內部定義一個游標(Node* m_current);
2、遍歷開始前將游標指向位置為 0 的數據元素;
3、獲取游標指向的數據元素;
4、通過結點中的 next 指針移動游標。
提供一組遍歷相關的函數,以線性的時間復雜度完成遍歷鏈表,如下

遍歷函數原型設計如下:
bool move(int i, int step = 1);
bool end();
T current();
bool next();
下來我們來看看優化后的 LinkList.h 是怎樣的,如下
LinkList.h 源碼
#ifndef LINKLIST_H
#define LINKLIST_H
#include "List.h"
#include "Exception.h"
namespace DTLib
{
template < typename T >
class LinkList : public List<T>
{
protected:
struct Node : public Object
{
T value;
Node* next;
};
mutable struct : public Object
{
char reserved[sizeof(T)];
Node* next;
} m_header;
int m_length;
int m_step;
Node* m_current;
Node* position(int i) const
{
Node* ret = reinterpret_cast<Node*>(&m_header);
for(int p=0; p<i; p++)
{
ret = ret->next;
}
return ret;
}
public:
LinkList()
{
m_header.next = NULL;
m_length = 0;
m_step = 1;
m_current = NULL;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool insert(int i, const T& e)
{
bool ret = ((0 <= i) && (i <= m_length));
if( ret )
{
Node* node = new Node();
if( node != NULL )
{
Node* current = position(i);
node->value = e;
node->next = current->next;
current->next = node;
m_length++;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to insert new element ...");
}
}
}
bool remove(int i)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
Node* current = position(i);
Node* toDel = current->next;
current->next = toDel->next;
delete toDel;
m_length--;
}
return ret;
}
bool set(int i, const T& e)
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
position(i)->next->value = e;
}
return ret;
}
T get(int i) const
{
T ret;
if( get(i, ret) )
{
return ret;
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Invaild parameter i to get element ...");
}
}
bool get(int i, T& e) const
{
bool ret = ((0 <= i) && (i < m_length));
if( ret )
{
e = position(i)->next->value;
}
return ret;
}
int find(const T& e) const
{
int ret = -1;
int i = 0;
Node* node = m_header.next;
while( node )
{
if( node->value == e )
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}
int length() const
{
return m_length;
}
void clear()
{
while( m_header.next )
{
Node* toDel = m_header.next;
m_header.next = toDel->next;
delete toDel;
}
m_length = 0;
}
bool move(int i, int step = 1)
{
bool ret = (0 <= i) && (i < m_length) && (step > 0);
if( ret )
{
m_current = position(i)->next;
m_step = step;
}
return ret;
}
bool end()
{
return (m_current == NULL);
}
T current()
{
if( !end() )
{
return m_current->value;
}
else
{
THROW_EXCEPTION(INvalidOPerationException, "No value at current position ...");
}
}
bool next()
{
int i = 0;
while( (i < m_step) && !end() )
{
m_current = m_current->next;
i++;
}
return (i == m_step);
}
~LinkList()
{
clear();
}
};
}
#endif // LINKLIST_H
main.cpp 源碼
#include <iostream>
#include "LinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
LinkList<int> list;
for(int i=0; i<5; i++) // O(1)
{
list.insert(0, i);
}
for(list.move(0); !list.end(); list.next()) // O(1)
{
cout << list.current() << endl;
}
return 0;
}我們來看看編譯結果
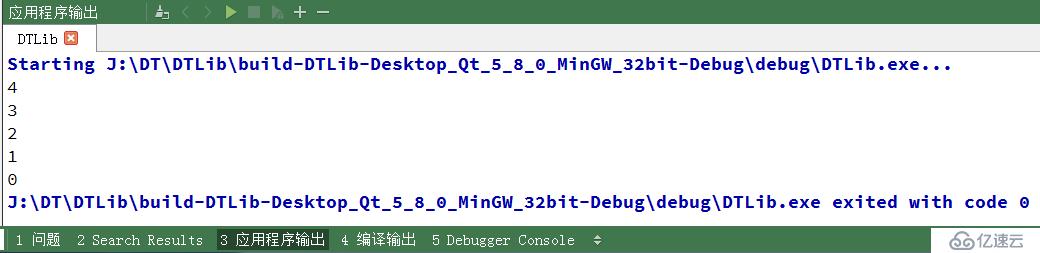
我們看到結果還是正確的,證明我們上面代碼的編寫是沒有錯誤的。我們再來分析下,它每次移動,移動后 current 指針就停在那塊,等到下次移動的時候還是從這塊開始移動。也就是說,每次遍歷的時候,它只需要遍歷一次就可以輸出結果了,這樣的話它遍歷的時間復雜度就為 O(1) 了。我們再來將 new 和 delete 操作封裝下,方便后面的使用,具體封裝如下
virtual Node* create()
{
return new Node();
}
virtual void destroy (Node* pn)
{
delete pn;
}然后將下面的 new 和 delete 操作全部換成 create 和 destory 函數。我們來試下將 main.cpp 測試代碼中移動的 step 改為 2,那么它便輸出的是偶數了。我們來看看結果

確實是輸出的只有偶數。那么我們移動的 step 為 10 呢?那它就應該只輸出 4 了,我們再來看看結果
現在我們的 LinkList 類已經近乎完美了,優化后的效率遍歷的時候極大的提高了。通過今天對 LinkList 優化的學習,總結如下:1、單鏈表的遍歷需要在線性時間內完成;2、在單鏈表內部定義游標變量,通過游標變量提高效率;3、遍歷相關的成員函數是相互依賴,相互配合的關系;4、封裝結點的申請和刪除操作更有利于增強擴展性。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





