溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Protobuf即Protocol Buffers,是Google公司開發的一種跨語言和平臺的序列化數據結構的方式,是一個靈活的、高效的用于序列化數據的協議。
與XML和JSON格式相比,protobuf更小、更快、更便捷。protobuf是跨語言的,并且自帶一個編譯器(protoc),只需要用protoc進行編譯,就可以編譯成Java、Python、C++、C#、Go等多種語言代碼,然后可以直接使用,不需要再寫其它代碼,自帶有解析的代碼。
只需要將要被序列化的結構化數據定義一次(在.proto文件定義),便可以使用特別生成的源代碼(使用protobuf提供的生成工具)輕松的使用不同的數據流完成對結構數據的讀寫操作。甚至可以更新.proto文件中對數據結構的定義而不會破壞依賴舊格式編譯出來的程序。
GitHub地址:https://github.com/protocolbuffers/protobuf
不同語言源碼版本下載地址:
https://github.com/protocolbuffers/protobuf/releases/latest
Protobuf的優點如下:
A、性能號,效率高
序列化后字節占用空間比XML少3-10倍,序列化的時間效率比XML快20-100倍。
B、有代碼生成機制
將對結構化數據的操作封裝成一個類,便于使用。
C、支持向后和向前兼容
當客戶端和服務器同時使用一塊協議的時候, 當客戶端在協議中增加一個字節,并不會影響客戶端的使用
D、支持多種編程語言
Protobuf目前已經支持Java,C++,Python、Go、Ruby等多種語言。
Protobuf的缺點如下:
A、二進制格式導致可讀性差
B、缺乏自描述
下載C++版本的Protobuf源碼protobuf-cpp-3.6.1.tar.gz
解壓Protobuf源碼:tar -zxvf protobuf-cpp-3.6.1.tar.gz
進入protobuf-3.6.1源碼目錄:cd protobuf-3.6.1
配置變量:./configure --prefix=/usr/local/protobuf
編譯:make
檢查、測試:make check
安裝:sudo make install
設置環境變量:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib
export PATH=$PATH:/usr/local/protobuf/bin檢查版本號:protoc --version
Protobuf提供了protoc編譯器,用于通過定義好的.proto文件來生成Java,Python,C++,Ruby,Objective-C,C#,Go等語言代碼。protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR --go_out=DST_DIR --ruby_out=DST_DIR --javanano_out=DST_DIR --objc_out=DST_DIR --csharp_out=DST_DIR path/to/file.proto
(1)導入目錄設置
IMPORT_PATH聲明了一個.proto文件所在的解析import具體目錄。如果忽略該值,則使用當前目錄。如果有多個目錄則可以多次調用--proto_path,會順序的被訪問并執行導入。-I=IMPORT_PATH是--proto_path的簡化形式。
(2)生成代碼指定
--cpp_out?:在目標目錄DST_DIR中產生C++代碼
--java_out?:在目標目錄DST_DIR中產生Java代碼
--python_out?:在目標目錄 DST_DIR 中產生Python代碼
--go_out?:在目標目錄 DST_DIR 中產生Go代碼
--ruby_out:在目標目錄 DST_DIR 中產生Ruby代碼
--javanano_out:在目標目錄DST_DIR中生成JavaNano
--objc_out:在目標目錄DST_DIR中產生Object代碼
--csharp_out:在目標目錄DST_DIR中產生Object代碼
--php_out:在目標目錄DST_DIR中產生Object代碼(3)導入proto消息文件指定
必須指定一個或多個.proto文件作為輸入,多個.proto文件可以只指定一次。雖然文件路徑是相對于當前目錄的,每個文件必須位于其IMPORT_PATH下,以便每個文件可以確定其規范的名稱。
(4)生成編程語言相關代碼
當用Protobuf編譯器來運行.proto文件時,編譯器將生成所選擇語言的代碼,相應語言的代碼可以操作在.proto文件中定義的消息類型,包括獲取、設置字段值,將消息序列化到一個輸出流中以及從一個輸入流中解析消息。
對C++語言,編譯器會為每個.proto文件生成一個.h文件和一個.cc文件,.proto文件中的每一個消息有一個對應的類。
對Java語言,編譯器為每一個消息類型生成了一個.java文件以及一個特殊的Builder類(用來創建消息類接口的)。
對Go語言,編譯器會為每個消息類型生成了一個.pb.go文件。
對Ruby語言,編譯器會為每個消息類型生成了一個.rb文件。
Protobuf中,消息即結構化數據。
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}Person消息格式有3個字段,在消息中承載的數據分別對應于每一個字段,其中每個字段都有一個名字和一種類型。
在一個消息文件.proto中可以定義多個消息類型,在定義多個相關的消息的時候較為有用。
// [START declaration]
syntax = "proto3";
package Company.Person;
import "google/protobuf/timestamp.proto";
// [END declaration]
// [START messages]
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
google.protobuf.Timestamp last_updated = 5;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person people = 1;
}
// [END messages].proto文件中非注釋非空的第一行必須使用Proto版本聲明,版本聲明如下:
syntax = "proto3";
如果不使用proto3版本聲明,Protobuf編譯器默認使用proto2版本。
Proto消息文件的命名如下:
packageName.MessageName.proto
packageName為package聲明的包名
MessageName為消息名稱
添加注釋可以使用C/C++/java風格的雙斜杠(//)語法格式。
.proto文件中可以新增一個可選的package聲明符,用來防止不同的消息類型有命名沖突。包的聲明符會根據使用語言的不同影響生成的代碼:
A、對于C++語言,產生的類會被包裝在C++的命名空間中。
B、對于Java語言,包聲明符會變為java的一個包,除非在.proto文件中提供了一個明確有java_package。
C、對于Go語言,包可以被用做Go包名稱,除非顯式的提供一個option go_package在.proto文件中。
Protobuf語法中類型名稱的解析與C++是一致的:首先從最內部開始查找,依次向外進行,每個包會被看作是其父類包的內部類。當然對于Company.Person以“.”分隔的是從最外圍開始的。
Protobuf編譯器會解析.proto文件中定義的所有類型名。 對于不同語言的代碼生成器會知道如何來指向每個具體的類型,即使它們使用了不同的規則。
字段類型包括標量類型和合成類型。
標量類型包括: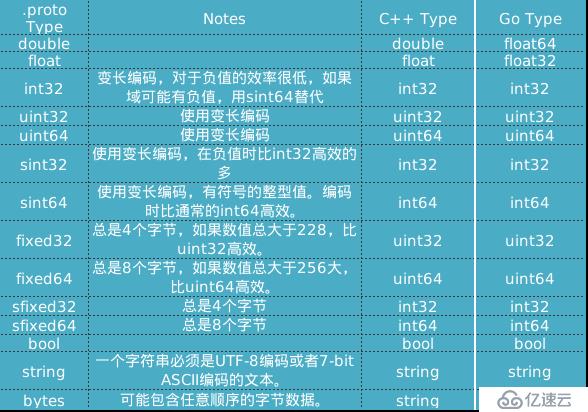
合成類型包括枚舉(enumerations)或其它消息類型。
在消息定義中,每個字段都有唯一的一個數字標識符。標識符用來在消息的二進制格式中識別各個字段,一旦使用就不能夠再改變。
最小的標識符可以從1開始,最大到2^29 - 1(536,870,911),不可以使用其中[19000-19999]( Protobuf協議實現中進行了預留,從FieldDescriptor::kFirstReservedNumber 到 FieldDescriptor::kLastReservedNumber)的標識號。如果非要在.proto文件中使用預留標識符,編譯時就會報警。
[1,15]內的標識號在編碼的時候會占用一個字節。[16,2047]之內的標識號則占用2個字節。所以應該為頻繁出現的消息元素保留[1,15]內的標識號。
消息的字段修飾符必須是如下之一:
A、singular:一個格式良好的message應該有0個或者1個該字段(但不能超過1個)。
B、repeated:在一個格式良好的消息中,該字段可以重復任意多次(包括0次),重復值的順序會被保留。
在proto3中,repeated的標量字段默認情況下使用packed。
如果通過刪除或者注釋所有字段,以后的用戶在更新消息類型的時候可能重用標識符。如果使用舊版本代碼加載相同的.proto文件會導致嚴重的問題,包括數據損壞、隱私錯誤等等。為了確保不會發生向前兼容可以為字段tag(reserved name可能會JSON序列化的問題)指定reserved標識符,Protobuf編譯器會警告未來嘗試使用相應字段標識符的用戶。
不要在同一行reserved聲明中同時聲明字段名字和標識符。
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}當一個消息被解析的時候,如果編碼消息里不包含一個特定的singular元素,被解析的對象所對應的字段被設置為一個默認值,不同類型默認值如下:
對于string,默認是一個空string
對于bytes,默認是一個空的bytes
對于bool,默認是false
對于數值類型,默認是0
對于枚舉,默認是第一個定義的枚舉值,必須為0
對于消息類型(message),字段沒有被設置,確切的消息是根據語言確定的,通常情況下是對應語言中空列表。
對于標量消息字段,一旦消息被解析,就無法判斷字段是被設置為默認值還是根本沒有被設置,應該在定義消息類型時注意。
當定義一個消息類型時,需要為消息中的某個字段指定預定義值序列中的一個值,此時可以使用枚舉定義預定以序列。如為Person消息添加一個PhoneType類型的字段,PhoneType類型的值可能是MOBILE,HOME,WORK。
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
google.protobuf.Timestamp last_updated = 5;
}每個枚舉類型必須將其第一個類型映射為0。
可以通過allow_alias選項為true,將不同的枚舉常量指定為相同的值,否則編譯器會在別名的地方產生一個錯誤信息。
enum EnumAllowingAlias {
option allow_alias = true;
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
enum EnumNotAllowingAlias {
UNKNOWN = 0; //EnumNotAllowingAlias中沒有設置allow_alias
STARTED = 1;
// RUNNING = 1;//error
}枚舉常量必須在32位整型值的范圍內。因為enum值是使用可變編碼方式的,對負數不夠高效,因此不推薦在enum中使用負數。
可以在一個消息定義的內部或外部定義枚舉,枚舉可以在.proto文件中的任何消息定義里重用。可以在一個消息中聲明一個枚舉類型,而在另一個不同的消息中使用枚舉(采用MessageType.EnumType的語法格式)。
當對一個使用了枚舉的.proto文件運行Protobuf編譯器的時候,生成的代碼中將有一個對應的enum(Java或C++),被用來在運行時生成的類中創建一系列的整型值符號常量(symbolic constants)。
在反序列化的過程中,無法識別的枚舉值會被保存在消息中。對支持開放枚舉類型超出指定范圍外的語言(例如C++和Go),未識別的值會被表示成所支持的整型;對封閉枚舉類型的語言中(Java),使用枚舉中的一個類型來表示未識別的值,并且可以使用所支持整型來訪問;在其它情況下,如果解析的消息被序列號,未識別的值將保持原樣。
可以將其它消息類型用作字段類型。對于同一個消息文件內部定義的消息,可以在其它消息內部直接引用消息類型;對于在其它消息文件定義的消息類型,可以通過導入其他消息文件中的定義來使用相應的消息類型。如使用google.protobuf.Timestamp消息類型需要導入相應消息文件:import "google/protobuf/timestamp.proto";
如果要在父消息類型的外部重用消息類型,需要以Parent.Type的形式使用。
Any類型消息允許在沒有指定.proto定義的情況下使用消息作為一個嵌套類型。一個Any類型包括一個可以被序列化bytes類型的任意消息以及一個URL作為一個全局標識符和解析消息類型。
為了使用Any類型,需要導入import google/protobuf/any.proto。
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}對于給定的消息類型的默認類型URL是type.googleapis.com/packagename.messagename。
不同語言的實現會支持動態庫以線程安全的方式去幫助封裝或者解封裝Any值。例如在java中,Any類型會有特殊的pack()和unpack()訪問器,在C++中會有PackFrom()和UnpackTo()方法。
Oneof定義用來代表在實現的時候,該組屬性中有且只能有一個被定義,不能出現多個。
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}上述定義中只能出現name或者sub_message的出現,不能同時出現,同時Oneof不能出現repeated域。重復傳遞值到Oneof多個域僅僅最后的會生效,其它的將被忽略掉。
如果要創建一個關聯映射,Protobuf提供了一種快捷的語法:
map<key_type, value_type> map_field = N;其中key_type可以是任意Integer或者string類型(除了floating和bytes的任意標量類型都可以),value_type可以是任意類型,但不能是map類型。
例如,創建一個Project的映射,每個Projecct使用一個string作為key:
map<string, Project> projects = 3;Map的字段可以是repeated。
序列化后的順序和map迭代器的順序是不確定的,所以不要期望以固定順序處理Map
當為.proto文件產生生成文本格式的時候,map會按照key 的順序排序,數值化的key會按照數值排序。
從序列化中解析或者融合時,如果有重復的key則后一個key不會被使用,當從文本格式中解析map時,如果存在重復的key。
向后兼容性問題
map語法序列化后等同于如下內容,因此即使是不支持map語法的Protobuf實現也可以處理數據:
message MapFieldEntry {
key_type key = 1;
value_type value = 2;
}
repeated MapFieldEntry map_field = N;如果想要將消息類型用在RPC(遠程方法調用)系統中,可以在.proto文件中定義一個RPC服務接口,Protobuf編譯器將會根據所選擇的不同語言生成服務接口代碼及stub。如要定義一個RPC服務并具有一個方法Search,Search方法能夠接收SearchRequest并返回一個SearchResponse,可以在.proto文件中進行如下定義:
service SearchService {
rpc Search (SearchRequest) returns (SearchResponse);
}最直觀的使用Protobuf的RPC系統是gRPC,由谷歌開發的語言和平臺中的開源的PRC系統,gRPC在使用Protobuf時非常有效,如果使用特殊的Protobuf插件可以直接從.proto文件中產生相關的RPC代碼。
如果不想使用gRPC,可以使用Protobuf用于自己的RPC實現。
Proto3支持JSON的編碼規范,便于在不同系統之間共享數據。
如果JSON編碼的數據丟失或者其本身是null,數據會在解析成Protobuf的時候被表示成默認值。如果一個字段在Protobuf中表示為默認值,會在轉化成JSON編碼的時候忽略掉以節省空間。
如果一個已有的消息格式已無法滿足新的需求,需要在要息中添加一個額外的字段,但同時舊版本寫的代碼仍然可用。可以使用更新消息解決,更新消息而不破壞已有代碼是非常簡單的。更新消息時規則如下:
A、不要更改任何已有字段的標識符。
B、如果增加新的字段,使用舊格式的字段仍然可以被新產生的代碼所解析。應該記住元素的默認值,新代碼就可以以適當的方式和舊代碼產生的數據交互。通過新代碼產生的消息也可以被舊代碼解析,但新增加的字段會被忽視掉。未被識別的字段會在反序列化的過程中丟棄掉,如果消息再被傳遞給新的代碼,新的字段依然是不可用的。
C、非required的字段可以移除。只要標識符在新的消息類型中不再使用(推薦重命名字段,例如在字段前添加“OBSOLETE_”前綴)。
D、int32, uint32, int64, uint64,和bool是全部兼容的,可以相互轉換,而不會破壞向前、 向后的兼容性。
E、sint32和sint64是互相兼容的,但與其它整數類型不兼容。
F、string和bytes是兼容的——只要bytes是有效的UTF-8編碼。
G、嵌套消息與bytes是兼容的——只要bytes包含該消息的一個編碼過的版本。
H、fixed32與sfixed32是兼容的,fixed64與sfixed64是兼容的。
I、枚舉類型與int32,uint32,int64和uint64相兼容(注意如果值不相兼容則會被截斷),然而在客戶端反序列化后可能會有不同的處理方式,例如,未識別的proto3枚舉類型會被保留在消息中,但表示方式會依照語言而定。int類型的字段總會保留他們的
J、可以添加新的optional或repeated的字段, 但必須使用新的標識符(消息中從未使用過的標識符,不能使用已經被刪除過的標識符)。
在定義.proto文件時能夠標注一系列的options。options并不改變整個文件聲明的含義,但卻能夠影響特定環境下處理方式。完整的可用選項可以在google/protobuf/descriptor.proto找到。
一些選項是文件級別的,意味著它可以作用于最外范圍,不包含在任何消息內部、enum或服務定義中。一些選項是消息級別的,意味著它可以用在消息定義的內部。當然有些選項可以作用在域、enum類型、enum值、服務類型及服務方法中。到目前為止,并沒有一種有效的選項能作用于所有的類型
optimize_for(文件選項): 可以被設置為LITE_RUNTIME,SPEED,CODE_SIZE。這些值將通過如下的方式影響C++及Java代碼的生成:?
SPEED (default): Protobuf編譯器將通過在消息類型上執行序列化、語法分析及其它通用的操作,生成的代碼最優。
CODE_SIZE:Protobuf編譯器將會產生最少量的類,通過共享或基于反射的代碼來實現序列化、語法分析及各種其它操作。采用CODE_SIZE方式產生的代碼將比SPEED要少得多,但操作要相對慢些。CODE_SIZE方式生成代碼中實現的類及其對外的API與SPEED模式都是一樣的,常用在一些包含大量的.proto文件而且并不盲目追求速度的應用中。
LITE_RUNTIME:Protobuf編譯器依賴于運行時核心類庫來生成代碼(即采用libprotobuf-lite替代libprotobuf)。libprotobuf-lite核心類庫由于忽略了一些描述符及反射,要比全類庫小得多。這種模式經常在移動手機平臺應用多一些。編譯器采用LITE_RUNTIME模式產生的方法實現與SPEED模式不相上下,產生的類通過實現MessageLite接口,但僅僅是Messager接口的一個子集。option optimize_for = CODE_SIZE;
cc_enable_arenas(文件選項):對于C++產生的代碼啟用arena allocation。
objc_class_prefix(文件選項):設置Objective-C類的前綴,添加到所有Objective-C從此.proto文件產生的類和枚舉類型。沒有默認值,所使用的前綴應該是×××薦的3-5個大寫字符,注意2個字節的前綴是蘋果所保留的。
deprecated(字段選項):如果設置為true則表示該字段已經被廢棄,并且不應該在新的代碼中使用。在大多數語言中沒有實際的意義。int32 old_field = 6 [deprecated=true];
java_package?(file option):指定生成java類所在的包,如果在.proto文件中沒有明確的聲明java_package,會使用默認包名。不需要生成java代碼時不起作用。
java_outer_classname?(file option):指定生成Java類的名稱,如果在.proto文件中沒有明確聲明java_outer_classname,生成的class名稱將會根據.proto文件的名稱采用駝峰式的命名方式進行生成。如(foo_bar.proto生成的java類名為FooBar.java),不需要生成java代碼時不起任何作用
objc_class_prefix?(file option): 指定Objective-C類前綴,會前置在所有類和枚舉類型名之前。沒有默認值,應該使用3-5個大寫字母。注意所有2個字母的前綴是Apple保留的。
Proto文件編碼規范如下:
A、描述文件以.proto做為文件后綴。
B、除結構定義外的語句以分號結尾,結構定義包括:message、service、enum;rpc方法定義結尾的分號可有可無。
C、Message命名采用駝峰命名方式,字段命名采用小寫字母加下劃線分隔方式。
D、Enums類型名采用駝峰命名方式,字段命名采用大寫字母加下劃線分隔方式。
E、Service與rpc方法名統一采用駝峰式命名。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





