溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
樸素貝葉斯(Naive Bayes)算法的核心思想是:分別計算給定樣本屬于每個分類的概率,然后挑選概率最高的作為猜測結果。
假定樣本有2個特征x和y,則其屬于分類1的概率記作p(C1|x,y),它的值無法直接分析訓練樣本得出,需要利用公式間接求得。
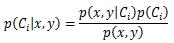
其中p(Ci)表示訓練樣本中分類為Ci的概率,它等于Ci樣本數除以樣本總數。
p(x,y)表示滿足2個特征的樣本概率,它等于第1特征等于x且第2特征等于y的樣本數除以樣本總數。可以發現p(x,y)與當前在計算哪個分類概率是無關的,因此實際計算中可以忽略它,不會影響結果。
p(x,y|Ci)表示Ci分類中滿足2個特征的樣本概率,在樸素貝葉斯算法中,認為x與y是相互獨立的,因此p(x,y|Ci)=p(x|Ci)*p(y|Ci),其中p(x|Ci)表示Ci分類的樣本中第1個特征等于x的概率。
上面的例子中只給定了2維的情況,實際可以擴展到N維,由于假定各特征相互獨立,因此p(w|Ci)總是可以分解求得的。
上C#代碼:
using System;
using System.Collections.Generic;
using System.Linq;
namespace MachineLearning
{
/// <summary>
/// 樸素貝葉斯
/// </summary>
public class NaiveBayes
{
private List<DataVector<string>> m_TrainingSet;
/// <summary>
/// 訓練
/// </summary>
/// <param name="trainingSet"></param>
public void Train(List<DataVector<string>> trainingSet)
{
m_TrainingSet = trainingSet;
}
/// <summary>
/// 分類
/// </summary>
/// <param name="vector"></param>
/// <returns></returns>
public string Classify(DataVector<string> vector)
{
var classProbDict = new Dictionary<string, double>();
//得到所有分類
var typeDict = new Dictionary<string, int>();
foreach(var item in m_TrainingSet)
typeDict[item.Label] = 0;
//為每個分類計算概率
foreach(string type in typeDict.Keys)
classProbDict[type] = GetClassProb(vector, type);
//找最大值
double max = double.NegativeInfinity;
string label = string.Empty;
foreach(var type in classProbDict.Keys)
{
if(classProbDict[type] > max)
{
max = classProbDict[type];
label = type;
}
}
return label;
}
/// <summary>
/// 分類(快速)
/// </summary>
/// <param name="vector"></param>
/// <returns></returns>
public string ClassifyFast(DataVector<string> vector)
{
var typeCount = new Dictionary<string, int>();
var featureCount = new Dictionary<string, Dictionary<int, int>>();
//首先通過一次遍歷,得到所需要的各種數量
foreach(var item in m_TrainingSet)
{
if(!typeCount.ContainsKey(item.Label))
{
typeCount[item.Label] = 0;
featureCount[item.Label] = new Dictionary<int, int>();
for(int i = 0;i < vector.Dimension;++i)
featureCount[item.Label][i] = 0;
}
//累加對應分類的樣本數
typeCount[item.Label]++;
//遍歷每個維度(特征),累加對應分類對應特征的計數
for(int i = 0;i < vector.Dimension;++i)
{
if(string.Equals(vector.Data[i], item.Data[i]))
featureCount[item.Label][i]++;
}
}
//然后開始計算概率
double maxProb = double.NegativeInfinity;
string bestLabel = string.Empty;
foreach(string type in typeCount.Keys)
{
//計算p(Ci)
double classProb = typeCount[type] * 1.0 / m_TrainingSet.Count;
//計算p(F1|Ci)
double featureProb = 1.0;
for(int i = 0;i < vector.Dimension;++i)
featureProb = featureProb * (featureCount[type][i] * 1.0 / typeCount[type]);
//計算p(Ci|w),忽略p(w)部分
double typeProb = featureProb * classProb;
//保留最大概率
if(typeProb > maxProb)
{
maxProb = typeProb;
bestLabel = type;
}
}
return bestLabel;
}
/// <summary>
/// 獲取指定分類的概率
/// </summary>
/// <param name="vector"></param>
/// <param name="type"></param>
/// <returns></returns>
private double GetClassProb(DataVector<string> vector, string type)
{
double classProb = 0.0;
double featureProb = 1.0;
//統計訓練樣本中屬于此分類的數量,用于計算p(Ci)
int typeCount = m_TrainingSet.Count(p => string.Equals(p.Label, type));
//遍歷每個維度(特征)
for(int i = 0;i < vector.Dimension;++i)
{
//統計此分類下符合本特征的樣本數,用于計算p(Fn|Ci)
int featureCount = m_TrainingSet.Count(p => string.Equals(p.Data[i], vector.Data[i]) && string.Equals(p.Label, type));
//計算p(Fn|Ci)
featureProb = featureProb * (featureCount * 1.0 / typeCount);
}
//計算p(Ci|w),忽略p(w)部分
classProb = featureProb * (typeCount * 1.0 / m_TrainingSet.Count);
return classProb;
}
}
}代碼中Classify方法以最直接直觀的方式實現算法,易于理解,但是由于遍歷次數太多,在訓練樣本較多時效率不佳。ClassifyFast方法減少了遍歷次數,效率有一定提升。兩者的基礎算法是一致的,結果也一致。
需要注意實際運行中有可能遇到多個分類概率相同或者每種分類概率都是0的情況,此時一般是隨便選取一個分類作為結果。但有時要小心對待,比如用貝葉斯識別垃圾郵件時,如果概率相同,甚至是兩個概率相差不大時,都要按非垃圾郵件來處理,這是因為沒識別出垃圾郵件造成的影響遠小于把正常郵件識別成垃圾造成的影響。
還是用上回的毒蘑菇數據進行一下測試,這回減少點數據量,選取2000個樣本進行訓練,然后選取500個測試錯誤率。
public void TestBayes()
{
var trainingSet = new List<DataVector<string>>();
var testSet = new List<DataVector<string>>();
var file = new StreamReader("agaricus-lepiota.txt", Encoding.Default);
//讀取數據
string line = string.Empty;
for(int i = 0;i < 2500;++i)
{
line = file.ReadLine();
if(line == null)
break;
var parts = line.Split(',');
var p = new DataVector<string>(22);
p.Label = parts[0];
for(int j = 0;j < p.Dimension;++j)
p.Data[j] = parts[j + 1];
if(i < 2000)
trainingSet.Add(p);
else
testSet.Add(p);
}
file.Close();
//檢驗
var bayes = new NaiveBayes();
bayes.Train(trainingSet);
int error = 0;
foreach(var p in testSet)
{
var label = bayes.ClassifyFast(p);
if(label != p.Label)
++error;
}
Console.WriteLine("Error = {0}/{1}, {2}%", error, testSet.Count, (error * 100.0 / testSet.Count));
}測試結果是錯誤率是0%,有點出乎意料。改變訓練樣本與測試樣本,錯誤率會有變化,比如與上一篇相同條件時(7000個訓練樣本+1124個測試樣本),測試出的錯誤率是4.18%,與隨機猜測50%的錯誤率相比,已經相當精確了。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





